Как создать лицо человека онлайн
В этой статье речь пойдет о генерировании лица человека со схожими к реальности параметрами и проработкой каждой детали. Если вас интересует создание изображения для аватарки, рекомендуем использовать другие онлайн-сервисы, детально ознакомившись с соответствующей инструкцией в статье по ссылке ниже.
Подробнее: Создаем аватар онлайн
Способ 1: FaceMaker
Если стоит задача спроектировать детальные человеческие черты лица без дальнейшего применения модели или сохраняя ее только в качестве изображения, оптимальным вариантом для разработки подобного проекта станет онлайн-сервис FaceMaker.
Перейти к онлайн-сервису FaceMaker
- На главной странице FaceMaker подтвердите создание нового проекта.
- Разработчики сайта собирают небольшую сводку о тех, кто использует их инструмент. Для начала укажите год своего рождения (можно не выбирать настоящий год, если не хотите).

- Затем ответьте на остальные вопросы, указав пол, страну, и отметив варианты в строках о компьютерных играх и фильмах. Подтвердите соглашение с правилами использования онлайн-сервиса и щелкните по кнопке «Start».
- Ознакомьтесь с основной информацией о создании нового образа, а затем нажмите «Continue».
- После загрузки редактора по центру отобразится исходная модель: в отношении нее и осуществляется дальнейшее редактирование.
- Пройдемся по порядку, разобрав каждый присутствующий в FaceMaker блок. Первый называется «Eyebrows» и позволяет настроить положение, цвет и линию роста бровей. Перемещайте ползунки, чтобы сразу посмотреть полученные изменения.
- При наведении курсора на раздел «Nose» объект сразу же будет перемещен в подходящее положение, что относится и к любой другой области редактирования. Изменяйте состояние ползунков соответствующих пунктов, чтобы настроить форму носа, его высоту, длину и положение.
- В разделе «General» собрано сразу несколько важных параметров. Здесь настраивается цвет волос, кожи, детализированность кожи лица и гендерная принадлежность персонажа. Отдельного внимания заслуживает ползунок «Style». С его помощью можно сделать лицо более похожим на реальное или мультипликационное.
- Далее идет «Cheeks and Jaw». Эта категория сосредоточена на настройке щек и подбородка. Лицо, как обычно, будет перемещено в удобный для редактирования вид, а изменения отобразятся сразу же при перемещении ползунков.
- Первая категория «Eyes» отвечает за редактирование глаз. Настройте их размер, разрез, цвет и расстояние между ними.
- К разделу «Outer face Parts» (внешние части лица), относится изменение размера глаз, горла и лба.
- Губы и рот настраиваются через «Mouth». Тут задается глубина, размер каждой губы и положение рта.
- По завершении редактирования нажмите «Finished», чтобы получить готовое лицо.
- Вы можете щелкнуть ПКМ по готовому изображению, чтобы скачать его на компьютер в качестве картинки.


Готовые проекты применяются разработчиками FaceMaker в качестве анализа и развития нейронных сетей в одном из немецких университетов, поэтому вы можете задать описание своему персонажу, помогая развитию технологий.
Способ 2: Character Creator
Character Creator — бесплатный инструмент для создания полноценного персонажа, которого можно использовать в дальнейшем для анимирования или добавления в игру. Функциональность этого онлайн-сервиса направлена только на создание лица, что происходит так:
Перейти к онлайн-сервису Character Creator
- Перед началом работы с персонажем потребуется выбрать пол, кликнув по одной из фигур левой кнопкой мыши.
- После на экране появится таблица с возможными оттенками цвета кожи, где вам предстоит отыскать подходящий.
- Настройку тела рассматривать не будем и сразу же перемещаемся в раздел «Head» через меню слева.
- Первая категория называется «Body_head». Выберите ее левым кликом мыши, а затем справа определите форму будущего лица.
- Далее перемещайтесь в «Ears», чтобы точно по такой же схеме настроить внешний вид ушей.
- В «Iris» выбирается тип глаза.
- Через отдельную категорию «Pupils» можно задать одну из трех форм зрачка, а также дополнительно выбрать предпочитаемый цвет.
- Следом идет категория «Nose», где доступно несколько самых популярных форм носа. Укажите один из них, а затем сразу же посмотрите результат, накладывающийся на модель.
- В Character Creator присутствуют самые разные вариации бороды и усы, которые можно посмотреть через «Facialhair». Тут же настраивается цвет и полностью убирается волосяной покров на лице.
- Через категорию «Hair» происходит примерно то же самое, но только для волос на голове.
- Есть возможность и наложения веснушек в «Freckles».
- Если требуется, чтобы на лице персонажа изначально проявлялись какие-то эмоции, ознакомьтесь со списком доступных выражений, подобрав подходящее.
- По завершении убедитесь, что персонаж был создан правильно, а затем щелкните «Download».
- Выберите тот вариант, где изображено только лицо, и скачайте его на компьютер.
- Готовое изображение с лицом будет скачано в формате SVG.

Если вы впервые сталкиваетесь с форматом SVG, наверняка возникнет вопрос о том, как его открыть. Для этого можно использовать ряд специальных программ и даже обычный браузер. Кроме этого поддерживается конвертирование в тот же JPG или PNG при помощи онлайн-сервисов. Более детально эти темы раскрываются в других статьях на нашем сайте по ссылкам ниже.
Подробнее:
Открываем файлы векторной графики SVG
Конвертирование фотографий разных форматов в JPG онлайн
Способ 3: Generated Photos
Онлайн-сервис Generated Photos значительно отличается от других, поскольку позволяет получить фото лица реального человека с заранее заданными параметрами внешности. Некоторым пользователям требуется именно такой формат изображения, поэтому давайте разберемся с этим инструментом.
Некоторым пользователям требуется именно такой формат изображения, поэтому давайте разберемся с этим инструментом.
Перейти к онлайн-сервису Generated Photos
- После перехода на главную страницу Generated Photos нажмите «Browse photos».
- Используйте первый раздел «Face», чтобы указать, будет ли целевое фото натуральным или обработанным при помощи вспомогательных средств.
- Через «Sex» задайте пол человека, фото которого хотите подобрать.
- Сортируйте и по возрасту, отметив маркером какой-либо пункт. Можно выбрать как ребенка, так и человека средних лет, пожилого.
- Поддерживается фильтр по этнической принадлежности. Это может быть афроамериканец, латиноамериканец, белый или азиат.
- Далее самое время перейти к деталям, выбрав цвет глаз.
- Точно по такому же принципу определяется и цвет волос.
- В завершение остается указать их длину.
- Последняя категория называется «Emotion», то есть вы можете указать, какую эмоцию должен выражать человек на фото. Пока Generated Photos только развивается, поэтому выбор вариантов небольшой.
- По готовности нажмите «Apply», чтобы применить фильтры.
- Ознакомьтесь с результатами и кликните по подходящему снимку.
- Задайте цвет заднего фона и нажмите «Download» для авторизации через соцсети и скачивания фото в формате изображения.
 Пока Generated Photos только развивается, поэтому выбор вариантов небольшой.
Пока Generated Photos только развивается, поэтому выбор вариантов небольшой.Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
Генератор лиц онлайн — NEZLOP.RU
Пользователям, вебмастерам или художникам постоянно требуются фейковые изображения людей. Обычно за таким отправляются на фотостоки, предполагая что здесь они оригинальные. Чтобы убедиться в обратном обратите внимание: под каждым фото сотни и тысячи просмотров. Помогут найти новые лица онлайн генераторы.
Быстро создать облик человека
На сайте, о котором пойдет речь, вы сможете быстро и без дополнительных настроек создать уникальную внешность человека.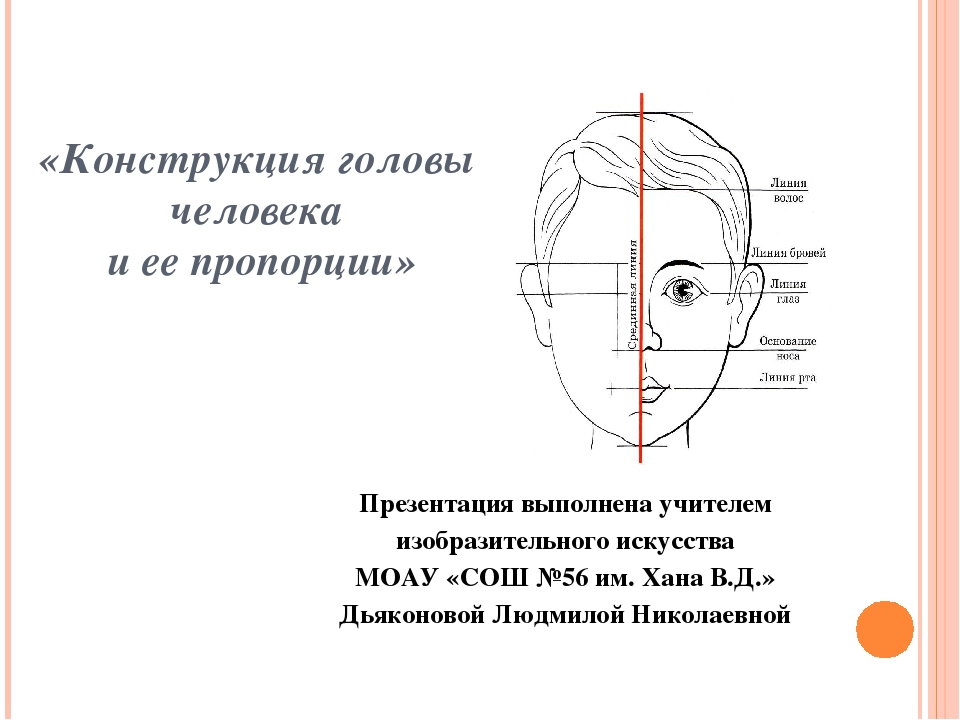 При переходе на страницу https://thispersondoesnotexist.com/ скрипт автоматически складывает разные признаки внешности из других экземпляров лица: губы, рот, глаза, волосы и т.д. И на весь экран появляется изображение нового, ранее невиданного человека.
При переходе на страницу https://thispersondoesnotexist.com/ скрипт автоматически складывает разные признаки внешности из других экземпляров лица: губы, рот, глаза, волосы и т.д. И на весь экран появляется изображение нового, ранее невиданного человека.
Лицо человека, созданное в программе
Сайт работает на технологии StyleGAN 2. Об этом сообщается в отдельном текстовом блоке. Генератор лиц работает следующим образом: чтобы получить очередной результат, нажмите на кнопку Обновить в вашем браузере. Каждый раз, возвращаясь на страницу, на экране видим новых людей.
При этом возникает подозрение: не водит ли нас за нос онлайн-сервис? Возможно, обновляя страницу, на экране возникают люди из какой-нибудь галереи?
Читайте еще: Генератор подписей онлайн.
Как проверить фото на уникальность
Поисковики Гугл и Яндекс самые большие в глобальной сети архивы с картинками. Поэтому отложим прочие сервисы для проверки изображений на сходство в сторону.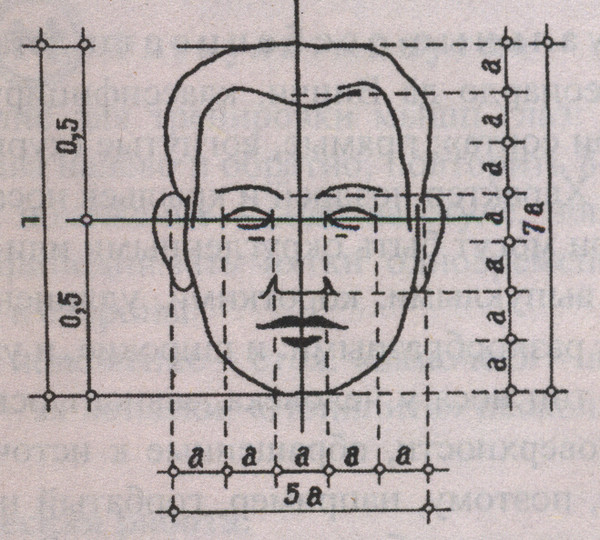 И воспользуемся одной из поисковых систем.
И воспользуемся одной из поисковых систем.
- Открываем Яндекс и выбираем в меню Картинки;
Картинки Яндекс
- Справа выбираем кнопку для поиска по фото;
- Нажимаем Выберите файл и находим подготовленный скриншот в папке ПК или смартфона.
Несуществующий человек проверка на уникальность
Теперь среди других результатов поиска по картинке можно определить, является ли сгенерированное лицо оригинальным. В нашем случае фото оказалось уникальным, были похожие, но точные совпадения отсутствовали.
Интересное по теме: Лучше генераторы названий онлайн.
Генератор человеческих лиц
Генерация людских обликов решает многие вопросы, связанные с поиском фотографий реального человека. Они работают таким образом, что не оставляют сомнений насчет подлинности изображения. Вы можете убедиться в этом сами.
Генератор человеческих лиц онлайн
Следующий сервис Ydalenka.ru. В нем можно получить сразу много результатов.
- Находим в нижней части параметры настройки;
Параметры генератора
- Выберите количество показываемых картинок на странице;
- Нажмите на кнопку Генерировать.
Чтобы скачать полученную картинку, нажмите по ней правую кнопку мыши. Затем выберите пункт Сохранить изображение.
Сохранить картинку на ПК
Создать мультяшное лицо онлайн
В компьютерной игре Skyrim после продолжительного вступления писарь спрашивает, кем является герой. И тут компьютер дает возможность выбрать расу и собственный облик персонажа. Эта возможность не уникальна. Своего героя собрать как конструктор предлагают разные игры. По такому же принципу сайт Gallerix предлагает сложить собственное мультяшное лицо.
- Выберите свой пол в редакторе;
Укажите свой пол
- Выберите форму лица из предложенных элементов в блоке;
Форма лица в блоке
- Внизу расположен блок с оттенками кожи, которые можно применить к аватару;
- Лицо можно увеличить, уменьшить, повернуть при помощи кнопок рядом с лицом;
- Поочередно выбирайте нос, рот и уши, придавая им правильную форму;
Выберите тип носа, глаз, ушей
- В верхней ленте вкладок изменяются глаза, волосы, фоны и одежда;
- В нижней части расположены кнопки, при помощи которых аватар можно создать автоматически из случайно сгенерированных элементов лица. А также кнопки Поделиться, Сбросить, Скачать и Gravatar.
Меню формы
 А также кнопки Поделиться, Сбросить, Скачать и Gravatar.
А также кнопки Поделиться, Сбросить, Скачать и Gravatar.Сервис Граватар — это глобальная система комментариев, которая прикреплена к множествам сайтов в интернете. По умолчанию в комментариях пользователю присваивается случайная иконка. Но теперь вы можете быть более узнаваемым, загрузив свой новый аватар в сервис.
Составить фоторобот бесплатно
Программы для составления фотороботов раньше можно было увидеть лишь в фильмах про детективов и полицию. Но теперь есть возможность использовать генератор онлайн, чтобы собрать лицо по частям из готовых элементов. Нужно только подбирать подходящий размер и форму частей лиц, чтобы получился похожий образ на определенного человека.
Сервис Фоторобот можно использовать для развлечения, собрав копию своего друга. Такой подарок будет оценен вместе с вашим чувством юмора. Осталось научиться пользоваться этим инструментом.
- Находим внизу блок с кнопками и пустым полем. Здесь мы будем составлять свой фоторобот. Под ним находятся элементы лица: борода, волосы, нос, усы и прочее;
Форма для рисования лица
- Выберите первый элемент, который вам проще остальных будет подобрать;
Части лица для составления фоторобота
- Если выбранная форма головы не подходит совсем, нажмите на одну из кнопок Библиотека. Тогда элемент сменится и станет другой формы. Нажимайте кнопку, пока не найдете похожий;
Настройка лица человека
- Голова может быть увеличена по ширине или высоте при помощи кнопок на панели справа;
- Если выбрать следующую часть, например, борода и нажать на кнопку Библиотека, то смена формы будет происходить только для бороды;
- Чтобы изменить цвет выбранного элемента лица, нажмите на кнопку с блокнотом и карандашом. И выберите палитру цветов внизу;
Функция смены цвета фоторобота и рисования дополнительных штрихов
- Для внесения своих правок в составляемый фоторобот, нажмите еще раз на блокнот и дорисуйте портрет. Толщина грифеля меняется с выбором размера точек в меню;
- Чтобы удалить весь фоторобот с полотна нажмите на кнопку перезагрузки страницы на панели браузера. Или на кнопку Очистить в меню.
 Здесь мы будем составлять свой фоторобот. Под ним находятся элементы лица: борода, волосы, нос, усы и прочее;
Здесь мы будем составлять свой фоторобот. Под ним находятся элементы лица: борода, волосы, нос, усы и прочее; Толщина грифеля меняется с выбором размера точек в меню;
Толщина грифеля меняется с выбором размера точек в меню;Если у вас получилось создать нужное изображение, нажмите на кнопку Скачать. И укажите место для загрузки в устройстве.
Лица, которые были составлены другими пользователями
Кнопка Галерея открывает страницу, напоминающую форум. Где пользователи делятся своими шедеврами и вместе обсуждают их.
Расскажите, удалось ли вам найти подходящий онлайн генератор лиц на этой странице. Поделитесь составленным фотороботом в комментариях.
AI генератор лиц — создание фотографий несуществующих людей
Generated.photos — позволяет вам сгенерировать фотографию несуществующего человека. Генерация произвольных реалистичных лиц с помощью ИИ. Все портреты модельные. Вы можете генерировать необходимые вам фотографии онлайн и использовать их в коммерческих целях.
https://generated.photos/faces
- Профессиональное освещение, камеры и макияж
- Профессиональная команда: от фотографов до инженеров машинного обучения
- Разнообразие: демография, мимика и позы.
Генерируйте фотографии людей любого возраста, пола и разного этнического происхождения.
Где используются сгенерированные фотографии
От приложений, которые помогают людям проверять слепоту, до журналистов, защищающих личные данные, или даже корпоративных компаний, которые хотят продемонстрировать свое программное обеспечение клиентам.
- Игровая индустрия
- Анонимность в сети
- Арт-проекты
- Коммерческий сегмент
- Научные исследования
- Дизайн
Используя сгенерированное лицо, вы можете быть спокойны за авторское право и не обязаны будете выплачивать фото модели дивиденты до конца жизни.
Генерация произвольных реалистичных лиц с помощью ИИ.
В UI дизайне этот сервис можно использовать в качестве аватар для проекта.
Часто, подобный проект может выручить когда вам надо сделать продукт с таргетом на разные рынки.
Другие похожие проекты
Есть еще один интересный проект на эту тему. Разработчик Филипп Ван, когда-то работающий в Uber, создал сайт Thispersondoesnotexist.com — генератор лиц людей, которых не существует в реальной жизни.
Генератор лиц
Проект построен на решении StyleGAN, код которого компания Nvidia опубликовала в открытый доступ на GitHub. При каждом заходе на страницу создается реалистичный портрет человека. При этом все лица уникальны и ни разу не повторяются.
⚡ Если тебе понравился этот материал, ты можешь подписаться на мой Instagram / Facebook / Medium / Linkedin. Там ты найдешь больше интересных материалов о дизайне.
Создание реалистичного портрета от Arthur Hernandes
Arthur Hernandes рассказал о своем подходе к созданию реалистичных персонажей на примере проекта Cabal Patriarch, выполненного с помощью Zrush, Maya и V-Ray. Прототипом персонажа стал актер Джеймс Кромвель.
Перевод статьи с портала 80 level
Знакомство
Привет, я Артур Эрнандес, художник по персонажам. Мне 31 год и я живу в Сан-Пауло, крупнейшем городе Бразилии. Я работаю в индустрии CG уже почти 16 лет. Из моих недавних проектов можно выделить участие в создании бразильского CG-фильма и основанной на нем игры, а в этом году мне довелось поработать художником по персонажам над игрой Skydome.
Мне всегда нравились видеоигры, поэтому эта индустрия стала для меня естественным выбором. Я начал свою карьеру аниматором и занимался моделированием персонажей в качестве хобби. Когда я понял, что моя страсть к моделированию затмила интерес к анимации, я решил сменить вид деятельности.
Идея и референсы
Сначала я провел исследование. Мне всегда нравился уровень реализма, который крупные компании, вроде Blizzard и Blur, демонстрировали в своих синематиках, поэтому я захотел сделать проект в этом стиле. Моей целью было создать персонажа в позе, которая раскрывала бы его историю. «Патриарх Кабала» была одной из моих любимых карт Magic: The Gathering, и я решил, что этот персонаж отлично подойдет.
Первым делом нужно было найти референсы лица. Поскольку я хотел сделать как можно более реалистичную работу, то стал искать актеров, из которых получился бы убедительный патриарх. Я решил, что лучшим выбором будет Джеймс Кромвель и начал поиски референсов из фильмов, в которых он играл. Большинство фотографий я взял из второго сезона Американской истории ужасов. Референсы из фильмов хороши тем, что вы видите лицо актера с разных ракурсов и при разном освещении, поэтому замечаете детали, которых может быть не видно на отдельных фото.
Другим важным аспектом этого процесса является планка качества, которую вы ставите перед собой. В этом отношении полезно взглянуть на работы классных художников. Для меня это Rafael Grassetti, Steve Lord, Adam Skutt, Vimal Kerketta, Kris Costa и другие.
Самой главной трудностью стал недостаток моего внимания. Изначальная цель была слишком общей, поэтому я не смог качественно проработать все элементы персонажа. Я решил первым делом сосредоточиться на голове, и только когда она будет сделана наилучшим образом, переходить к работе над остальными частями Патриарха. Процесс создания реалистичного лица – очень непростая задача. Сложнее всего, как обычно, сделать модель похожей на референс. Важно понимать, что это итеративный процесс, поэтому мне потребовалось создать несколько голов до того, как получилась финальная версия.
Скульптинг
Процесс скульптинга был очень прост. Я начал с Dynamesh с несколькими уровнями сабдива и сделал грубый блокаут черепа. Затем я добавил общую форму носа, глаз и тд. Я хотел сделать базу для моей модели. После этого я начал размещать части лица в соответствии с их местоположением на лице актера. Шаг за шагом я задавал форму носа, расстояние между глазами, форму рта и тд, пока не получил желаемый результат. Затем я сфокусировался на создании вторичных форм – мимических морщин, складок кожи, переломов форм и тд. Стоит отметить, что на этой стадии я обычно работаю без симметрии, чтобы добавить модели реализма.
Детализация
После создания первичных и вторичных форм я перешел к детализации. Области возрастных изменений я создавал с помощью кистей Standart и Clay. Для морщин и углублений я использовал Dam Standart, чтобы подчеркнуть их и сделать более выразительными. При работе над складками кожи, расположенными рядом друг с другом, я применял Pinch и Inflate.
Для элементов, вроде пор кожи, я использовал альфу с режимом кисти Drag Rectangle, чтобы создать основу, а затем добавлял детализацию вручную.
Полигонаж финальной модели – около 6 млн. полигонов.
Глаза
Я обычно начинаю создание глаз с двух сфер: одна – для роговицы, вторая – для склеры, радужки и зрачка. Однако на этот раз я применил иной подход и создал три отдельных меша: первый для склеры и роговицы, второй для радужки и третий – для зрачка.
Сделав базовую модель глаза, я импортировал ее в Zbrush и покрасил с помощью Zspotlight, используя фото настоящего глаза как референс. Идея в том, чтобы сначала создать цветовую карту и на ее основе скульптить детализацию. Для этого я превратил ее в маску и использовал кисти Standart и Inflate, чтобы добавить новые детали. Затем я использовал кисть Clay для создания неоднородной поверхности. И наконец, я применил аналогичный подход к радужке: нарисовал цветовую карту, сделал из нее маску и заскульптил детализацию.
Для шейдера глаза я использовал V-Ray Mtl с некоторыми текстурными картами для контроля необходимых параметров – Reflection, Opacity, Albedo и Normal. Шейдер был очень простым и эффект реалистичности получился, в основном, благодаря скульптингу и хорошему освещению, которое дало интересное отражение в глазах.
Кожа
Поскольку я хотел получить как можно более реалистичную модель, то использовал FastSkin Shader в V-Ray. Он симулирует поведение реальной кожи в виртуальном окружении. После назначения шейдера я изменил его параметры. Увеличил Translucency, что усилило интенсивность рассеиваемых лучей, откорректировал Sub-surface color, чтобы получить нужный тон кожи, и Scatter color, что позволило получить эффект света, проникающего под кожу. Перед тем, как перейти к покраске карт, я нашел референсы кожи в интернете, чтобы облегчить этот процесс.
Карту Albedo я создавал в Zbrush и начал с того же цвета, что использовал для параметра Sub-scatter (возможно, он имеет ввиду Sub-surface color). Затем я нарисовал красный цвет на более «теплых» областях лица, после чего добавил синего и зеленого. В конце я добавил пигментные пятна, которые могут появляться на коже пожилых людей.
Получив карту Albedo, я создал карты Specular и Glossiness. Изначально я сделал их черного цвета, а затем добавил светлых пятен в области, которые я хотел сделать ярче, например, нос, рот, лоб и мешки под глазами. Далее я совместил карту Cavity, сделанную в Zbrush, с черно-белой версией Albedo, чтобы получить большую вариативность ярких областей на поверхности лица.
Чтобы перенести заскульпченную детализацию из Zbrush, я экспортировал карты Displacement и Bump, объединил их и подключил результат к шейдеру как карту Displacement.
Волосы
Процесс создания волос довольно прост. В Zbrush я замаскировал необходимые области, применил Fibermesh и «причесал» волосы кистью Move. Сами волосы были созданы с помощью системы nHair в Maya. У каждого типа волос ( брови, щетина и т.д.) своя группа nHair. Это позволяет назначать им специфические особенности, изменяя необходимые параметры.
Чтобы создать nHair, вам потребуется 3D-объект, который будет служить рабочей поверхностью. После этого вы можете применить nHair и добавить уже имеющиеся волосы Fibermesh. У каждого типа волос будет своя конфигурация nHair. Как правило, я всегда корректирую следующие параметры:
- Thinning — чтобы сгенерировать более естественные пряди разного размера
- Clump Width — увеличиваю это значение для лучшего распределения корней волос по поверхности
- Сlump Width Scale — отвечает за разделение кончиков волос
Для всех волос персонажа был использован шейдер V-Ray Hair, но его параметры индивидуально настраивались для каждой области. Например, для тонких волосков (нос, уши) параметр Opacity был снижен на 40%, это сделало их менее заметными. Чтобы получить более красивую бороду, я изменил Primary Amount, чтобы приглушить ее яркость и Primary Glossiness, чтобы подчеркнуть светлые участки.
Освещение и рендер
Для рендера я выбрал V-Raу, потому что мне нравятся результаты, которые я получаю при использовании шейдера кожи. Кроме того, это относительно простая система.
Я хотел показать модель при нейтральном освещении без добавления цветов. Я выстроил стандартную схему. Рисующий свет над моделью придает ей объем и подсвечивает тени, особенно в области глаз. Два контурных светильника создают эффект светопроницаемости, который присутствует благодаря SSS (подповерхностному рассеиванию). Заполняющий свет снизу корректирует тени на шее и под носом. Помимо этого я вставил два светильника типа Dome с HDRI-картами чтобы дополнить схему освещения: один из них подсвечивает темные области а другой улучшает отражаемость материалов.
Что касается шейдеров, я применил FastSkin для лица V-Ray Mtl для глаз и V-Ray Hair на волосы.
Интервью провел Kirill Tokarev.
Подписывайтесь на нас в Facebook, Telegram, Vkontakte, Pinterest.
Создание лица персонажа для игры «OnAir» / Хабр
Добрый день! Меня зовут Дарья, я 3d artist в студии RainStyle production. В настоящее время мы заняты разработкой игры в жанре Sci-fi horror под названием “On Air”.
Игра рассказывает о загадочных событиях, случившихся с главным героем, который волей случая остановился в американском отеле Алгол. Это происшествие полностью поменяет его жизнь и заставит столкнуться с неизвестным.
Это наш первый игровой проект и в нем мы стараемся добиться максимальной реалистичности персонажей, передать их эмоции и характер. Поэтому для их создания было принято решение использовать технологию сканирования лиц. В рамках задач проекта нам потребуется две степени детализации персонажей: под рендер — для синематика и low poly — для использования в самой игре.
Игра On Air разрабатывается на движке Unreal Engine 4. Мы планируем написать несколько статей, в которых расскажем подробно этапы подготовки персонажа.
В данный момент мы занимаемся созданием демо версии игры, которая уже в скором времени появится в Стиме. В данной статье я расскажу о начальном этапе создания лица главного персонажа нашей игры.
Часть 1
На изображении ниже представлены некоторые из эмоций, которые мы получили после обработки сканов.
В основном они утрированы и не кажутся реалистичными. Это было сделано намеренно. Дело в том, что в основе данного метода создания лица лежит принцип смешивания форм «Blend shapes». То есть, каждая из этих эмоций будет применяться не в “чистом” виде, а в совокупности с другими. Об этом я подробнее расскажу в самом конце статьи. Для начала, надо разобраться, что делать с отсканированной головой и как мы можем ее использовать. Очевидно, что топология скана не позволяет применить ее в качестве модели, но при помощи запечения карты нормалей мы получим основные черты лица, морщины, поры, неровности или шрамы. Также со скана мы можем извлечь текстуру базового цвета.
В этом нам поможет программа Wrap 3.3. Она широко используется для обработки отсканированных моделей. С ее помощью мы будем проецировать нашу будущую модель головы на сканы.
Часть 2
Для начала необходимо создать так называемый базовый меш. То есть, нейтральное выражение лица, которое будет лежать в основе всех эмоций. Наш скан с нейтральной эмоцией выглядит так:
Программа Wrap 3.3 имеет нодовую систему, то есть все функции представлены в виде узлов (нод), которые связаны друг с другом цепочкой.
Выбор нод осуществляется при помощи клавиши Tab. При помощи нод «LoadGeom» и «LoadImage» подгружаются скан с нейтральной эмоцией и соответствующая ему текстура. Для этого в окне File Names надо указать путь. В настройках ноды «LoadGeom» вы можете выбрать различные режимы отображения геометрии (на изображении ниже отключена функция wireframe). Также здесь можно изменить цвет геометрии (не работает, если подключена текстура), координаты и масштаб.
Далее необходимо подгрузить базовый меш, который будет проецироваться на данный скан. Найти его можно на вкладке “Gallery”. Здесь представлено множество уже готовых эмоций. В данном случае я выбираю Basemesh.
Basemesh стоит приближенно сопоставить со сканом. Для этого можно использовать оси координат.
Чтобы спроецировать базовый меш на скан, я использую ноду Wrapping. При наведении курсора мыши на узлы ноды, высвечивается подсказка: первый узел, Floating geometry — предназначен для проецируемой геометрии, второй узел, Fixet geometry — для фиксированного объекта, по которому будет проецироваться геометрия (в нашем случае это скан с нейтральной эмоцией).
Чтобы запустить вычисление, необходимо отметить точки на обеих моделях, которые будут соответствовать друг другу. Для этого используется нода Select points, которая подключается в соответствующие узлы моделей. Выбрав эту ноду, следует перейти на вкладку Visual Editor. Включенная функция Sync views позволяет синхронизировать камеры для левого и правого окон.
Если проецируемая модель содержит полигоны, которые должны оставаться на месте, необходимо выделить их, воспользовавшись функцией Select Polygons. Иначе могут возникнуть артефакты, связанные со внутренними деталями меша.
Для применения ноды Select Polygons используется вкладка Visual Editor. Здесь можно выделить те полигоны, которые Модели из галереи разбиты на полигруппы, это упрощает задачу: их можно выделить или снять выделение на верхней панели.
Я выделяю внутренние детали горла, ноздри, крайние лупы век и нижнюю часть шеи.
После этого модель будет проецироваться корректно.
Также, для большей детализации, можно использовать ноду Subdivide. Она подключается к базовому мешу и все ноды, которые находятся ниже, подсоединяются к ее нижнему узлу (Output).
Далее, надо запечь текстуру со скана на базовый меш. Для этого применяется нода Transfer Texture. Узел Source geometry подключается к модели, с которой будет запекаться текстура. В нашем случае это скан. Узел Target geometry подключается к базовому мешу, но уже не к ноде LoadGeom, а к ноде Wrapping, так как мы будем использовать уже измененную, спроецированную геометрию.
В настройках этой ноды можно выбрать качество запеченной текстуры. После этого стоит добавить ноду Extrapolate Image, чтобы заполнить прозрачные места, и сохранить полученную текстуру с помощью ноды Save Image и нажатием кнопки Compute current frame. Геометрия сохраняется аналогично, с помощью ноды Save Geom.
Часть 3
После того, как мы получили нейтральную эмоцию и текстуру для нее, можно перейти к получению геометрии для других эмоций. Для этого подгружаем модель скана и Basemesh с текстурами.
Далее нужно выровнять Basemesh по скану. Для начала можно сопоставить модели приближенно, воспользовавшись координатными осями.
Нода, которая позволяет более точно выравнивать модели относительно друг друга — Rigid Alignment. В узел Floating geometry подсоединяется геометрия, которую необходимо выровнять. В узле Fixed geometry, соответственно, будет статичная геометрия (в нашем случае это скан).
При использовании ноды Rigid Alignment необходимо использовать ноду Select Points:
На моей модели есть контрольные маркеры, которые упрощают задачу при выборе точек. Для выравнивания моделей относительно друг друга точки необходимо ставить на тех частях лица, которые незначительно меняются при изображении той или иной эмоции. В случае с данной эмоцией это лоб, верхняя часть носа, шея и тп. Также, точки желательно расставлять по всем сторонам модели (то есть, например не только на лице, но и на затылке и ушах).
В результате мы получаем выровненные относительно друг друга модели:
В настройках ноды Rigid Alignment есть функция “Match skale”. Она используется, если модели необходимо выровнять также по масштабу.
После этого можно заняться проекцией базового меша на скан. Для этого мы будем использовать ноду Optical Flow Wrapping (оптический поток). Она позволяет выравнивать геометрию по текстуре скана. При этом полученная в итоге текстура эмоции будет полностью совпадать с текстурой базового меша за исключением складок, морщин и других изменений. Все неровности кожи и поры при использовании этого метода остаются на своих местах.
Перед использованием оптического потока, как и в первом случае, используется нода Select Polygons:
Таким образом, неподвижные части головы останутся на месте.
Также можно использовать ноду Select Points. Здесь указываются точки на подвижных частях лица:
Далее переходим в настройки оптического потока. В окне Visual Editor вокруг модели появились камеры, которые можно корректировать.
Сверху есть выпадающее меню, с помощью которого можно перейти в вид из камеры. По умолчанию их 13. Надо поставить их так, чтобы лицо полностью попадало в кадр.
По рекомендации разработчиков почти все настройки я оставляю по умолчанию за исключением параметров Resolution final и Optical flow smoothness final:
После этого, можно нажать Compute и посмотреть результат:
После того, как меш ровно спроецировался на скан, нужно запечь текстуру. делается это по тому же принципу, что и в первой части статьи:
В итоге, если совместить полученную текстуру с текстурой базового меша, добавятся некоторые детали, но, при этом, контрольные точки будут совпадать:
После этого, текстуру и полученную геометрию можно сохранить.
В итоге, мы получили меш новой эмоции с текстурой.
Часть 4
Метод Blend shapes позволяет “смешивать эмоции”. Для этого нужно подгрузить уже полученные меши в ноду Blend shapes.
Я подгрузила в первый узел нейтральную эмоцию. Двигая ползунки в настройках ноды, можно выбрать, насколько сильно будет выражена та или иная эмоция. Для того, чтобы этот метод сработал, модели должны иметь одинаковую топологию.
Результат
Вышеописанный процесс — это лишь небольшая часть очень объемной работы. После получения LowPoly моделей головы необходимо было создать карты нормалей, rougness, subsurface и т.д., а также настроить шейдер (в нашем случае мы настраивали шейдер для рендера и для движка). Также отдельно создавались глаза, одежда и волосы. Стоит также отметить, что данную задачу выполняли всего три человека. Это был наш первый опыт в создании высокодетализированного персонажа. Мы остались довольны результатом, но будем стремиться к большему.
3d моделирование лица человека по фотографиям.
В последнее время очень популярна услуга создания 3D-модели человека по фотографиям для её последующей печати в виде гипсополимерной 3D-статуэтки. Самым непростым и высокохудожественным этапом в этой услуге является моделирование лица. В данной статье мы вам поэтапно расскажем, на что стоит обращать внимание 3D-моделлерам при создании 3D-лиц, какие при этом бывают сложности и как их избежать.
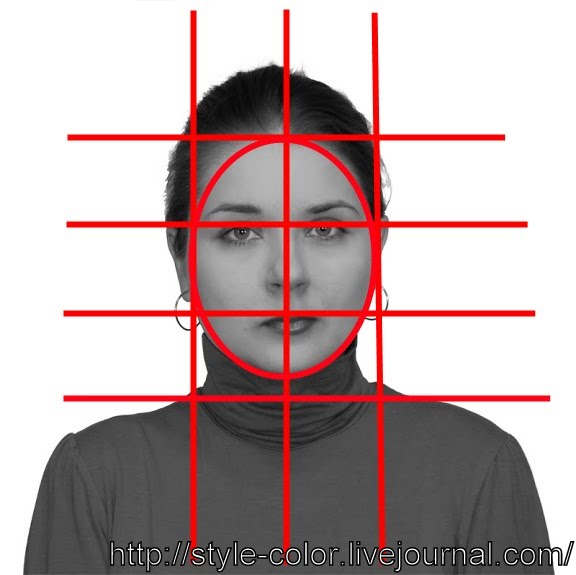
1. Конструкция черепа
При создании портрета очень важно учитывать конструкцию черепа, так как кость является единственной недеформируемой частью головы (за исключением движения нижней челюсти).
Мышечные ткани, жир и кожа, деформируются в зависимости от эмоций на лице.
Очень важно при создании экстремальных (в плане деформации) эмоций не потерять наличие конструкции черепа. При «потере черепа» лицо может выглядеть неестественно, хотя при этом и может быть согласовано клиентом.
Для начала определим такое понятие как Лицевой индекс.
Лицевой индекс помогает более точно установить пропорции соотношений между шириной скул и длины лица, чтобы избежать ошибки узких лиц.
В среднем высоту головы от подбородка до макушки можно взять за 22-23 сантиметра (оно может меняться в зависимости от формы черепа). А за среднюю ширину головы 16 см (расстояние измеряемое между точками эурион). Как правило, расстояние между точками эурион является самым широким на черепе.
Неверную конструкции головы выдает ощущение диспропорций лица, дисгармония масс, излишняя карикатурность. Наиболее это заметным становится при просмотре головы с экстремальных ракурсов, с углов с которых обычно никто никогда не фотографирует.
Как пример, с нижнего ракурса, голова кажется вытянутой и узкой. Лобные массы кажутся сильно выставленными вперед, контур нижней челюсти пропадает. Подбородок кажется непропорциональным по отношению к низу лица.
Однако ощущения некорректной анатомии и фактические нарушения конструкции лица могут совершенно некоррелировать между собой.
Например, на ниже приведённом примере, может казаться, что лоб сильно выставлен вперед, однако ошибка не во лбу, а в некорректной постановке скул и в ширине головы.
Лицо может казаться яйцеобразным не из-за ширины щек, а из-за отсутствия конструкций нижней челюсти и неверной постановки ширины точек черепа эурион (точек над ухом).
Изменение угла источников света и добавление перспективы, очень помогают определить нарушения в конструкции лица.
2. Портрет.
Создание верной конструкции черепа — это половина дела. Без портретных сходств лицо не получится узнаваемым, хоть конструкция лица и несет в себе большинство портретно-узнаваемых особенностей головы и лица в целом. Например, выступающий подбородок или выпирающие губные массы, что является следствием выступающих вперед зубов или же массивность надбровных дуг. Но речь идет больше о чертах лица, как об особенной совокупности костных масс, мышечных масс, процента жировых масс, качества и количества кожных масс. В нашем мире огромное количество людей, но людей с одинаковыми лицами практически единицы. Каждое лицо по-своему уникально и отличается от другого лица своим набором уникальных черт и форм. Это и есть ключевой момент для создания портрета, понять особенности моделируемого лица.
Рассматривание других лиц и их сравнение со «средним» лицом помогает быстрее выделить конкретные уникальные отличия моделируемого лица от среднестатистического лица.
3. Объективное лицо и искажения объективного лица.
Предположим, есть некое объективное лицо, характерное конкретному периоду жизни человека, с конкретной эмоцией, которое необходимо создать. Объективное лицо, это то самое «истинное лицо» или же, то лицо которое мы получим при трехмерном сканировании. Но художник воспринимает это лицо только через фотографии. И это восприятие может быть в разной степени коррелировать с объективным лицом. Заказчик же, видел владельца лица воочию, и воспринимает лицо с этих же фотографий совершенно по-другому, в его голове возникает совершенно другая база образов отличная от базы образов художника. Мы думаем, что это и является проблемой между ожиданиями клиента и поисками проделанными художником. Поэтому для создания наиболее объективного портрета нужно отбросить как можно больше субъективных или искажающих факторов.
Вот примерный перечень искажающих восприятие факторов.
- Угол обзора камеры или «сила» перспективы.
- Низкое разрешение изображения, его явная пикселизация или же расфокусировка лица.
- Качество освещения на фотографии.
- Наличие заграждающих факторов (очки, маски, кепки, падающие тени на лице)
- Отсутствие достаточного количества ракурсов и плохие углы съемки.
- Посторонние эмоции и разный возраст на фотографиях.
- Качество кожи, наличие пост эффектов и фильтров.
- Метод наложения фотографии на модель.
- Привыкание к лицу.
Начнем по порядку.
3.1. Угол обзора камеры очень сильно влияет на воспринимаемую форму лица.
Чем больше угол обзора, тем сильнее вытягивается лицо. Все что ближе к камере становится крупнее, все что дальше от камеры, меньше и уходит как бы во внутрь. Такие фотографии чаще всего получаются при съёмке лица вблизи камеры и при создании селфи. Чем дальше сфотографирован человек, тем меньше в его лице перспективных искажений и тем сильнее перспектива стремится к фотографии.
3.2. Сжатие изображения.
Чем сильнее сжато фото, тем недостовернее воспринимается форма лица. Как правило, фотографии большого разрешения читаются лучше, и мозгу не нужно прилагать дополнительные усилия для распознавания черт лица. С клиентом же ситуация состоит по-другому. Клиент даже в сильно сжатой фотографии низкого разрешения увидит своего друга, любимого, коллегу. Все это связано с механизмом распознавания образов. При просмотре «пиксельного» фото, у клиента в голове, уже есть библиотека образов связанная с этим конкретным человеком и он с легкостью по некачественному фото может описать его конкретные черты. Однако настоящим источником информации клиента является не фото, а его голова. Желательно меньше ориентироваться на некачественные фото, так как они могут в голове 3D-художника посеять сомнения об объективном лице.
3.3. Качество и углы освещения, ракурс.
Это те самые искажения, которые применяются профессиональными фотографами для преображения фотографируемой модели. Не все лица, красивы со всех ракурсов и не на все лица хорошо падает свет. Именно этого и стараются избежать, когда фотографируют. Фотографии человека, присланные клиентом, всегда чуть более привлекательные, чем объективная реальность и менее привлекательные, чем профессиональная фотосессия. Но для создания верной формы головы, для отображения всех черт лица, нужно увидеть все стороны лица. Поэтому наличие как можно большего количества фотографий и их анализ, создание подобных фотосклеек, помогут построить в голове образ объективной головы.
Наличие разных ракурсов позволит соотнести позиции тех или иных черт и масс лица в пространстве.
3.4. Заграждающие факторы.
Тут все просто. Очки, падающие тени на лице, портят восприятие лица. В глазах клиента, лицо с заграждающими факторами воспринимается абсолютно так же как и объективное лицо, а в глазах художника это полная неопределенность.
3.5. Отсутствие профиля.
Тот случай, когда все присланные фото только в фас и анфас. Наш мозг заточен под распознавание образов. Поэтому сделав поиск лица лишь только по анфасам, мы можем сказать, похоже, лицо или нет, и то не с полной уверенностью, так как присутствуют другие виды искажений. Клиент же знает, как выглядит объективное лицо, и несхожесть сразу распознает. Единственный вариант решения проблемы — это сделать как можно больше поисков и отправить клиенту, в надежде, что он сможет описать профиль либо найти дополнительные материалы по лицу.
3.6. Эмоции и возраст.
Эмоции очень сильно могут изменить восприятие объективного лица. Особенно в тех случаях, когда требуется конкретная эмоция, а на присланных фото она совершенно другая. В таких случаях лучше опираться на конструкцию лица, на костные структуры. Например, при открытой улыбке, мягкие массы лица очень сильно меняются и меняют восприятие лица, нежели чем на лице без эмоций. Однако костные массы, при этом остаются неизменными. Для создания улыбок надо опираться на анатомические материалы, сканы и экорше лиц с улыбками. И соотносить динамику деформаций лиц в примере с динамикой на конкретном объективном лице. Особенно в тех случаях, когда улыбка есть только в анфас.
Зачастую присылаемые фотографии сделаны в разные периоды жизни человека. Надо учитывать, что форма головы, лица, его черт меняется из года в год. Кроме того, помимо изменения мягких мышечных и кожных масс, меняются также и костные массы. А значит, с возрастом меняется и конструкция черепа. В итоге, более молодые лица воспринимаются иначе, чем более возрастные и тут нужен общий анализ фотографий. Какие черты сильнее сохраняются с возрастом, по какому принципу меняется лицо с возрастом. Зачастую, молодые лица могут сбивать художника с толку при моделировании состарившегося лица.
3.7. Макияж, фотошоп.
Использование фильтров и макияжа, еще один способ уйти от объективной реальности и исказить визуальное восприятие лица. Как правило, лица девушек на фото и в жизни две совершенно разные стихии. Девушки хотят выглядеть привлекательнее, чем они есть на самом деле. В таких случаях похожая конструкция лица и гладкая упругая кожа уже сделают большой вклад в портретное сходство. Однако порой бывает тяжело определить конструкцию лица на «зафотошопленных» фото. Также надо учитывать и то, что объективные формы могут не такими, какими они кажутся на фотографии, и придётся искать любые зацепки в других ракурсах. Сильно бликующая кожа тоже портит восприятие формы лица, в этом случае с фотографией можно поработать в фотошопе и заглушить мешающие блики.
3.8. Метод наложения фотографии на модель.
Этот метод используется для быстрого поиска формы лица, однако при неправильном использовании этого метода, можно сильно исказить лицо. Для того чтобы избежать подобных искажений, нужно правильно выставить перспективу и ракурс. Найти точки опоры и оси лица. Одна из таких вспомогательных осей, это линия между основанием носа и мочкой уха. Угол поворота анфас-профиль можно ровнять по линии глаз. При этом нужно обязательно учитывать перспективные искажения. Так как два фото при разных полях зрения и углах обзора (например, профиль и полуанфас) при наложении никогда не сведут модель в единый объективный образ.
Негативная сторона такого метода ещё и в том, что лицо может сойтись с фото, даже может быть в некотором проценте случаев согласовано, но фактически в печати будет выглядеть совершенно иначе и расходиться с объективным лицом. Например, в печати лицо может быть более узким. Такие ошибки возникают при недостаточном количестве сведений фотографий с моделью, либо при неверном соотнесение углов лица на фото и угла модели. В идеале лицо должно сходиться с фото как минимум в 4-5 разных ракурсах.
3.9. Привыкание к лицу.
В процессе создания портрета художник привыкает к лицу. Из-за этого, некоторые уникальные особенности лица, воспринимаются им уже не так уникально, либо художник начинает принижать значение некоторые особенностей лица, дабы подчеркнуть его незначительные особенности. Проблема заключается в том, что когда мы первый раз видим лицо какого-то человека, то мы его воспринимаем, основываясь на своем опыте увиденных нами лиц. Наш мозг устроен так, что он склонен подчеркивать и запоминать различия или особенности лица, по сравнению с ранее увиденными лицами. Это требует минимум энергии для запоминания. При долгой же работе с лицом, мы принимаем все особенности этого лица как само собой разумеющееся и не отходящее от среднего лица. Это накладывает искажения на восприятие лица. Несмотря на все это, лицо увиденное в первый раз на фотографии, также может быть изначально неправильно прочитано и воспринято, но это уже совокупность всех вышеописанных проблем восприятия. Желательно делать перерывы при моделировании лица, отвлекаться, рассматривать другие лица. Этот простой метод помогает начать заново, свежо воспринимать создаваемое лицо.
С уважением, студия 3DKLON.
Создание лица в стиле аниме с использованием DCGAN и изучение его скрытого представления
Дата публикации Apr 13, 2019
Привет всем, это было время! Сегодня я хочу написать о своем результате изучения и эксперимента с другой техникой глубокого обучения, которая называется Generative Adversarial Network (GAN). Я учился и узнал об этом недавно. Думаю, было бы неплохо, если бы я поделился своим экспериментом со всеми.
фотоХитеш ЧоудхаринаUnsplash
GAN в основном о генерации чего-то. В этой статье я хочу рассказать об эксперименте по генерации лиц персонажей аниме. Я не только генерировал, но и экспериментировал с тем, что изображением можно манипулировать с помощью операции линейной алгебры над его скрытой переменной (вектором, который используется для генерации граней). Я также вижу, что сгенерированные лица следуют за статистическим распределением, которое действительно потрясающе.
Эта статья будет сосредоточена на учебнике, как сделать GAN с каждым объясненным шагом (с исходным кодом). Он будет предназначен для всех, кто интересуется ИИ, особенно для тех, кто хочет попрактиковаться в использовании глубокого обучения. Он также предназначен для всех, кто хочет научиться делать GAN впервые. Я напишу эту статью как можно проще, чтобы понять о ней. Я надеюсь, что читатели, прочитав эту статью, узнают, как работает GAN.
Если вы хотите лучше понять эту статью, я предлагаю вам знать хотя бы нейронную сеть и Convolution Neural Network (CNN).
В конце этой статьи есть ссылка на GitHub, если вы хотите узнать полный исходный код. Сейчас я дам ссылку на блокнот Python и ссылку Colab Laboratory в хранилище.
Изображение 0является одним из созданных граней аниме-персонажа, который мы создадим, используя изображение, сформированное моделью. Первое и второе изображение слева генерируется с помощью GAN. Третье — это добавление первой и второй граней (это можно назвать слиянием первой и второй граней).
Изображения 0: Пример сгенерированных лиц и слияние их лица. G + D = GAN
- Технология
- Введение
- Краткое описание о GAN
- Реализация
- Полученные результаты
- Урок выучен
- Вывод
- Послесловие
- вместилище
- источники
- Python 3.7
- Колаборатория: Бесплатная среда Jupyter для ноутбуков, которая не требует настройки и полностью работает в облаке. Есть графический процессор Tesla K80 или даже TPU! К сожалению, Tensorflow v2.0 alpha до сих пор не поддерживает TPU на момент написания этой статьи. К сожалению, DCGAN не может быть обучен через TPU.
- Keras: библиотека Python для глубокого обучения.
- Данные взяты изВот
Одна из тем, которая актуальна в области глубокого обучения, — это Генеративная состязательная сеть (GAN). ПредставленЯн Гудфеллоу и др.., Он может генерировать что-то с нуля без присмотра. В компьютерном видении. Есть много исследователей, исследующих и улучшающих его. Например, NVIDIA создатьреалистичный генератор лица с помощью GAN, Есть также некоторые исследования в области музыкипо использованию GAN, Моя предыдущая статья о создании музыки также может быть сделана с помощью GAN.
Изображение 1: бумага HoloGAN
Есть много вариантов типа GAN, разработанных исследователями там. Один из самых новых (к тому времени, когда я пишу эту статью)HoloGANкоторый может генерировать трехмерное представление из естественных изображений. Если вы посмотрите на то, как это можно сделать, это действительно удивительно. На самом деле, эти передовые GAN следуют основным принципам работы GAN. В каждом GAN есть два агента: ученик, дискриминатор и генератор (мы углубимся в эти термины позже). Чтобы узнать больше о передовых технологиях GAN, нужно знать, как работает базовый GAN.
Эта статья будет посвящена внедрению Deep Convolutional GAN (DCGAN), одного из вариантов GAN, предложенныхРэдфорд и др.По сути, это GAN со многими слоями свертки. Это одна из популярных нейронных сетей GAN. Мы будем строить архитектуру, отличную от предложенной в их статье. Хотя он и отличается, он все же дает хорошие результаты.
Одна из интересных особенностей GAN заключается в том, что он будет создавать свои скрытые переменные (1-D векторлюбойдлина), которой можно управлять линейной алгеброй. Пример наИзображение 0это один из примеров. Вектор первого лица (слева) добавляется к вектору второго лица. Тогда это даст третье лицо.
Это также дает некоторое интересное распределение данных. Каждая точка в распределении имеет разные виды граней. Например, данные с центром в среднем -0,7 будут иметь лицо с желтыми волосами.
Мы начнем с знания краткого описания о GAN.
Итак, что такое GAN?
Чтобы упростить его, это один из методов глубокого обучения, который используется для создания новых данных с нуля. Он работает неконтролируемым образом, что означает, что он может работать без пометки человека. Это будет делать данные на основе шаблона, который он изучает
На GAN есть некоторые характеристики, которые являются генеративной моделью, а именно:
- Узнает совместную вероятностьР (х, у)гдеИксэто вход иYвыход. Это будет делать вывод на основеР (х | у), учитывая выходу,это выведетИкс.Вы можете сказать, чтоYэто реальные данные в ГАН.
- Когда модель дается обучение реальные данныеY, он узнает характеристику реальных данных. Это будет учиться путем выявления реальных данныхпеременная скрытого представления объекта, Чтобы упростить его, он изучает функцию базового конструктора изображений в реальных данных. Например, модель может узнать, что лица построены по цвету глаз и волос. Эти два будут одной из основ, которые будут использоваться при создании граней. Изменяя его переменную, он также может изменять сгенерированные грани. Например, подняв переменную глаза, глаза станут чернее. Понижение этого сделает противоположное иначе.
- Он может построить распределение вероятностей, такое как нормальное распределение, которое можно использовать для предотвращенияостанец, посколькуостанецкак правило, очень редко встречается в дистрибутиве, его очень редко генерируют. Таким образом, GAN хорошо работает с реальными данными, которые имеют выбросы.
Итак, как это работает?
ГАН состоит из двух нейронных сетей,дискриминатора такжеГенератор, GAN заставит эти две сети сражаться друг с другом на игровой основе с нулевой суммой (теория игр). Это игра между этими агентами (сетями).состязательныйимя в GAN происходит от этой концепции.
Изображение 2: Иллюстрация Дискриминатор против Генератора. Изображение изменено и взято изВот
Генераторбудет генерировать некоторые поддельные данные идискриминаторбудет идентифицировать пару данных, которые имеют поддельные данные, сгенерированныеГенератори данные, взятые из реальных данных. ЦельГенераторв основном генерирует некоторые поддельные данные, которые предназначены аналогично реальным данным, и обманываетдискриминаторна выявление, какие данные являются реальными и поддельными. Цельдискриминаторэто сделать его умнее при выявлении реальных и поддельных данных. Каждый агент будет двигаться попеременно. Дуэли этих агентов, мы надеемся, что эти агенты станут сильнее, особенноГенератор.
Вы можете сказать, что они соперничают друг с другом. Главный геройГенератор, который стремится все лучше и лучше реализовывать нашу цель, учась на поединке у своего соперника.
Хорошо, другими словами,Генераторбудет имитировать реальные данные путем выборки распределения, которое изучено и предназначено для того же распределения, что и реальные данные. Он обучит свою нейронную сеть, которая может генерировать ее. Принимая во внимание, чтодискриминаторбудет обучать свою нейронную сеть контролируемой технике обнаружения поддельных и реальных данных. Каждая сеть будет обучать свою сеть попеременно.
Рисунок 3: Иллюстрация GAN по распределению обучающих данных. Фото сделано сВот,
Вот грубые шаги о том, как работает GAN:
- Генерировать случайный шум в распределении вероятностей, таких как нормальное распределение.
- Сделайте это в качестве входного сигнала нашей нейронной сети генератора. Будет выведен сгенерированныйподдельные данные, Эти шаги также могут означать, что мы выбираем некоторые данные из дистрибутива, который узнал генератор. Мы отметим шум как
z_nи сгенерированные данные какG(z_n),G(z_n)означает результат шума, обработанного генераторомг, - Мы объединяем сгенерированные поддельные данные с данными, которые взяты из набора данных (которые являются реальными данными). Сделайте их вкладом нашегоДискриминатор. Мы отметим это как D.Дискриминатор попытается узнать, предсказав, являются ли данные поддельными или нет. Обучите нейронную сеть, выполнив прямой проход и затем обратное распространение. ОбновляетDвеса.
- Затем нам нужно тренироватьГенератор, Нам нужно сделать
G(z_n)или поддельные данные, сгенерированные из случайных шумов в качестве входаD.Обратите внимание, что эти шаги только вводят поддельные данные вдискриминатор, Вперед пройтиG(z_n)вD.Используя нейронную сеть Discriminator, выполняя прямую передачу, предсказывайте, являются ли поддельные данные ложными или нет(D(G(z_n))), Затем выполните обратное распространение, где мы будем только обновлятьгвеса. - Повторяйте эти шаги до тех пор, пока мы не увидим, что генератор предоставляет хорошие поддельные данные или не достигнута максимальная итерация.
Иллюстрация выглядит следующим образом:
Изображение 4: Как работает GAN. Фото сделано сВот,
Обновив дистрибутив Генератора, чтобы он соответствовал Дискриминатору. Это то же самое, что минимизировать расхождение JS. Для получения дополнительной информации вы можете прочитатьэтостатья.
Чтобы наши агенты научились, убедитесь, чтодискриминатора такжегенератордоминировать друг над другом. Сделайте их как можно более сбалансированными и сделайтедискриминатора такжегенераторучиться одновременно Когдадискриминаторявляется слишком сильным (может различать поддельные и настоящие 100%),Генераторстать неспособным слишком чему-то научиться. Если в процессе обучения мы дойдем до этой точки, лучше ее закончить. Противоположность также имеет эффект, когдаГенераторсильнее, чем дискриминатор. Это вызывает Mode Collapse, где наша модель всегда предсказывает один и тот же результат для любых случайных шумов. Это одна из самых сложных и трудных частей GAN, которая может расстроить кого-то.
Если вы хотите понять больше, я предлагаю взглянуть и прочитать это удивительноестатья,
Итак, какова архитектура дискриминатора и генератора?
Это зависит от варианта ГАН, который мы будем разрабатывать. Поскольку мы будем использовать DCGAN, мы будем использовать последовательную пару уровней CNN.
Мы будем использовать собственную архитектуру, которая отличается от оригинальной статьи. Я следую архитектуре, используемой вФрансуа ШолеГлубокое обучение с Pythonкнига с некоторыми изменениями,
Конфигурация, которую мы использовали для построения DCGAN, выглядит следующим образом:
latent_dim = 64
height = 64
width = 64
channels = 3
Это означает, что у нас будет 64 измерения скрытых переменных. Высота и ширина наших изображений 64. Каждое изображение имеет 3 канала (R, G, B)
Вот импортированная библиотека и как данные подготовлены:
Вот архитектура:
Генератор
Он состоит из слоев свертки, одним из которых является слой транспонирования свертки. Чтобы увеличить размер изображения(32 -> 62), мы будем использовать параметр шага в слое свертки. Это сделано, чтобы избежать нестабильной подготовки ГАН.
Код
дискриминатор
Он также состоит из слоев свертки, где мы используем шаги для выполнения понижающей дискретизации.
Код
GAN
Чтобы сделать возможным обратное распространение для Генератора, мы создаем новую сеть в Керасе, котораяГенераторс последующимДискриминатор.В этой сети мы замораживаем все веса, чтобы их вес не менялся.
Это сеть:
Конфигурация тренинга следующая:
iterations = 15000
batch_size = 32
Конфигурация означает, что мы сделаем 15000 итераций. На каждой итерации мы обрабатываем 32 пакета реальных данных и поддельных данных (всего 64 для обучения дискриминатора).
После грубых шагов, которые я объяснил выше, вот как мы шаг за шагом обучаем DCGAN:
- Итерируйте до макс. Итерации следующих шагов
for step in tqdm_notebook(range(iterations)):
2. Генерировать случайный шум в распределении вероятностей, таком как нормальное распределение.
random_latent_vectors = np.random.normal(size = (batch_size, latent_dim))
generated_images = generator.predict(random_latent_vectors)
3. Объедините сгенерированные поддельные данные с данными, которые взяты из набора данных.
stop = start + batch_size
real_images = x_train[start: stop]
combined_images = np.concatenate([generated_images, real_images])
labels = np.concatenate([np.ones((batch_size,1)),
np.zeros((batch_size, 1))])
Обратите внимание, что мы используем последовательный сэмплер, где каждый данные будут сэмплированы последовательно до конца данных. Число, которое будет выбрано, равно размеру партии.
4. Добавьте шум на метку входа
labels += 0.05 * np.random.random(labels.shape)
Это важный трюк при обучении ГАН.
5. Тренируйте дискриминатор
d_loss = discriminator.train_on_batch(combined_images, labels)
6. Обучите генератор
random_latent_vectors = np.random.normal(size=(batch_size,
latent_dim))
misleading_targets = np.zeros((batch_size, 1))
a_loss = gan.train_on_batch(random_latent_vectors,
misleading_targets)
Обратите внимание, что мы создаем новые скрытые векторы. Не забывайте, что мы должны поменять этикетку. Помните, что мы хотим свести к минимуму потери, вызванные дискриминатором при неудачном прогнозировании фальшивок. Метка должна быть 1 дляmisleading_targets,
7. Обновите начальный индекс реального набора данных.
start += batch_sizeif start > len(x_train) - batch_size:
start = 0
Вот и все, вот полный код по обучению DCGAN:
Хорошо, пусть веселье начинается! Мы начнем с визуализации сгенерированных изображений в другой средней точке. Прежде чем мы это сделаем, позвольте мне сказать вам, что это результат вышеупомянутой модели, которая обучена 20000 шагов (итераций) и обучена с 30000 шагов. Модель тренируется около 7 часов (~ 4300 шагов в час). Я дам название модели с меньшим количеством шагов, какМодель Аа другой какМодель-B,
Вот так!
Как читать
Н ~ (х, у): латентные векторы, случайным образом генерируемые по нормальному распределению со среднимИкси стандартное отклонениеY
Результаты по скрытым векторам наN ~ (0,0,4)наМодель А:
Изображение 5: Модель сгенерированного лица-A N ~ (0, 0,4)
Не плохо, хотя есть изображения с асимметричным лицом.
Результаты по скрытым векторам наN ~ (0,1)наМодель А:
Изображение 6: Модель сгенерированного лица-A N ~ (0, 1)
Посмотрите на это .. модель произвела некоторыемерзостьлица там. Получается, что эта модель не совсем понимает распределение реальных данных. Это может быть лучше, когда стандартное отклонение ниже. DCGAN, который я обучил, еще не понял, как представлять точку данных, которая не слишком близка к средней точке. Я думаю, что это требует большей подготовки или более мощной архитектуры.
Давайте изменим архитектуру наМодель-B
Результаты по скрытым векторам наN ~ (0,0,4)наМодель-B:
Изображение 7: Сгенерированное лицо Модель-B N ~ (0, 0,4)
Хорошо, но лица становятся темнее. Интересно, что случилось с генератором.
Результаты по скрытым векторам наN ~ (0,1)наМодель-B:
Изображение 8: Модель сгенерированного лица-A N ~ (0, 1)
Хм, хорошо. большинство из них до сих пор содержитмерзостьлица. У некоторых из них были нормальные лица. Качество по-прежнему почти такое же, как у Model-A. Хорошо. Для следующих серий изображений давайте изменим стандартное отклонение как можно ближе к среднему. 0,4 будет лучшим.
Давайте проверим, генерируются ли наши скрытые векторы со средним средним значением -0,3 и 0,3 с использованием того же стандартного отклонения.
Результаты по скрытым векторам наN ~ (-0,3,0,4)наМодель А:
Изображение 9: Модель сгенерированного лица-A N ~ (0,3, 0,4)
Результаты по скрытым векторам наN ~ (0,3,0,4)наМодель А:
Изображение 10: Сгенерированное лицо Модель-A N ~ (-0,3, 0,4)
Результаты по скрытым векторам наN ~ (-0,3,0,4)наМодель-B:
Изображение 11: Сгенерированное лицо Модель-B N ~ (-0,3, 0,4)
Результаты по скрытым векторам наN ~ (0,3,0,4)наМодель-B:
Изображение 12: Генерированное лицо Модель-B N ~ (0,3, 0,4)
Видишь различия?
Да, посмотри на их волосы. В среднем 0,3 волосы в основном черные (некоторые из них коричневые). Напротив, в среднем -0,3 волоски в основном желтые. Да, наша модель может разместить грани в соответствующих точках. Также Модель-B генерирует лица, которые темнее, чем А.
Из того, что мы сделали выше, мы можем получить представление о том, как распределены данные, полученные в нашей модели.
Давайте подготовим это:
Рисунок 13: Распределение данных генератора
Исходя из результата, приведенного выше, я думаю, что чем меньше скрытый вектор означает, тем ярче будут волосы на лице, и чем больше скрытый вектор, тем на лицах будут более пурпурные волосы.
Чтобы убедиться, давайте посмотрим на среднее значение лица в каждой средней точке:
Мы строим эти скрытые вектора, среднее значение которых:
[-1, -0.8, -0.6, -0.4, -0.2, 0, 0.2 0.4, 0.6, 0.8 ]
Изображение 14: Средние лица из разных средних точек
Первый ряд — МОДЕЛЬ-А, а второй ряд — МОДЕЛЬ-В. Управляя средним значением скрытых векторов, мы можем видеть грань, которую он генерирует в этой точке. Мы это видим:
- Чем ниже точка вектора, тем желтее волосы.
- У него темное лицо посередине. Это означает, что средние лица в наборе данных имеют этот стиль.
- Положительная точка вектора — голубые волосы. Положительный латентный вектор также имеет более открытый рот при улыбке.
Основные операции линейной алгебры
Удивительно, не правда ли?
Пока нет, мы можем выполнить операцию линейной алгебры со скрытым вектором. Результат уравнения также может быть сгенерирован и иметь интересный результат. Возьмите результат от наших первых лиц перед вводным разделом:
G + D
Изображения 15: G + D = GAN
Ган лица является результатом добавления G с D. Вы можете видеть, что волосы становятся немного коричневыми. и волосы следуют за стилем D справа и G слева.
Ниже приведены результаты других операций:
G — D (Абсолют)
Изображения 16: G-D
Умножение по компонентам (G, D)
Изображения 17:Умножение по компонентам (G, D)
Манипулировать скрытыми векторами
Посмотрим, как будут создаваться изображения, если мы будем манипулировать измерением в скрытом векторе. Как я уже говорил ранее, модель научится скрытому представлению признаков. Итак, каждый элемент в скрытом векторе имеет своей целью генерацию изображения.
Чтобы сделать визуализацию, мы заморозим все элементы в векторах и изменим выбранное измерение, которое нужно проверить.
Изображения 18: Иллюстрация о том, что мы делаем в этом разделе
Например, мы хотим исследовать 1-й элемент в скрытом векторе, мы изменяем это измерение и оставляем остальные неизменными.
Мы сгенерируем несколько граней, которые имеют среднее значение в этих точках:
[-0.6, -0.3, 0.1, 0.3, 0.6]
Для каждой средней точки мы сгенерируем грани, размер которых в скрытом векторе будет изменен с этими значениями итеративно:
[-1.08031934, -0.69714143, -0.39691713, -0.12927146, 0.12927146, 0.39691713, 0.69714143, 1.08031934]
Позвольте визуализировать на нашем выбранном измерении: (Этот раздел будет использовать только МОДЕЛЬ-A)
28-е измерение:
Изображение 19: Результат изменения 28-й скрытой переменной в разных средних точках.
Каковы цели 28-й скрытой переменной?
Я думаю, это делает волосы ярче, меняет форму левого глаза, а также небольшие изменения на правом глазу. Поскольку он сжимает элемент в скрытый вектор длиной 64, одно измерение может иметь несколько целей.
Давайте посмотрим еще один!
5-е измерение
Рисунок 20: Результат изменения 5-й скрытой переменной разными способами
Что это за скрытые переменные цели?
Я думаю, что это как-то связано с левыми глазами, даже несмотря на то, как левые глаза отличаются для каждой средней точки. Это также делает волосы немного темнее. Что вы думаете?
11-е измерение
Рисунок 21: Результат изменения 11-ых скрытых переменных различными способами
Я думаю, это измерение заботит рот и правый глаз.
Другой пример для граней, которые генерируются из средних точек только путем подстройки скрытой переменной:
Изображение 22: Результат на лицах путем изменения скрытой переменной
Это оно. Мы можем построить любые измерения в скрытых векторах и посмотреть, каковы их цели. Хотя иногда трудно понять, каковы цели скрытой переменной.
Сравнить с реальными данными
Давайте попробуем 8 реальных лиц из набора данных:
Изображение 22: Реальные лица из набора данных
И образец 8 от генератора N ~ (0,1)для моделей A и B:
Изображение 23: Поддельные лица, сгенерированные генератором
Итак, если мы будем действовать как дискриминатор, можем ли мы различать настоящие и поддельные лица?
Нет сомнений, что мы все еще можем различать, какие лица являются поддельными и реальными. Для этого модели требуется больше обучения или мощная архитектура. Несмотря на это, наша модель все еще может генерировать форму лица в стиле аниме, и это здорово.
Ниже приведен урок, который я усвоил после исследования DCGAN:
- Тренировать ГАН сложно. Трудно создать стабильную архитектуру, не видя советов и хитростей от того, кто ее испытал. Особенно в отношении баланса мощности Дискриминатора и Генератора. Заставить ГАН не стать коллапсом — тоже непросто.
фотоПабло Мерхан МонтеснаUnsplash
- На самом деле, эти модели все еще не способны генерировать поддельные изображения. Тем не менее, он может создать некоторые хорошие лица, хотя и не так хорошо, как реальное. Мы все еще можем различать поддельные изображения и реальные изображения. Это связано с тем, что модель еще не поняла распределение реальных данных.
- Модель ухудшает свое качество примерно на 26000 ступеней. Вот где в моем эксперименте генератор стал слабым. Это нестабильность в ГАН. Мне нужно искать лучшую архитектуру, чтобы сделать это. Мы видим, что результат на модели B становится темнее.
- Итак, я разработал другую архитектуру с нормализацией партии и даже с Dropout Layer. Угадай, что? Есть два результата, которые я имею в настройке архитектуры. Распад модели и доминирование дискриминатора. Я думаю, что разработка архитектуры GAN не легка.
- Тем не менее, есть много советов и рекомендаций по разработке хорошего GAN, которые я не реализовал. Возможно, нестабильность модели можно уменьшить, следуя этим советам.
- Есть много вариантов GAN, которые являются более стабильными, такие как WGAN-DC и DRAGAN, и SAGAN. Мне нужно использовать другую архитектуру, которая может работать лучше, чем DCGAN.
В этой статье рассказывается о том, что делает GAN, и шаг за шагом рассказывается, как это сделать. После этого он сообщает нам интересную характеристику своего скрытого вектора, который показывает распределение данных, полученное генератором. Это показывает нам, что может сформировать распределение данных.
Латентный вектор может быть управляемым линейной алгеброй. Это может показать нам некоторые интересные вещи, такие как добавление двух скрытых векторов, которые объединят особенности каждой из этих граней. Также можно манипулировать, чтобы изменить грань на основе измененного элемента в скрытом векторе.
Несмотря на это, наша модель все еще не может сделать лицо, которое может заставить нас задуматься, является ли это лицо поддельным или нет. Это может все еще сформировать лица стиля аниме все же.
фотоЛемюэль БатлернаUnsplash
Вот и все, мой первый опыт работы с GAN. Я стал лучше понимать, что делает GAN. Я также хочу исследовать свое любопытство по поводу того, что узнал GAN. Вот они, это действительно удивительно, что они на самом деле делают. Генератор может отображать случайный вектор, генерируемый нормальным случайным шумом, в распределение данных. Он группирует грани в обозначенные точки данных.
Выполняя GAN, я фактически запускаю несколько моделей, которые я изготовил вручную. Ну, они с треском провалились. Одно время я думал, что модель может быть успешной, но она перейдет в режим коллапса (прогнозируемое лицо будет одинаковым независимо от скрытого вектора). я нашелfcholletхранилище о DCGAN и следуйте его архитектуре.
Так как я впервые проектирую GAN, я ожидаю много отзывов от всех по этому поводу. Просто укажи мне на ошибку, которую я совершил, так как я делаю это впервые. Простите, если результат не так хорош. Я просто хочу поделиться своим волнением по поводу ГАН. И поделитесь, как это сделать.
Тем не менее, это действительно весело, и я хочу поэкспериментировать с другим вариантом GAN, таким как WGAN-GP, DRAGAN или SAGAN. Я только немного разбираюсь в том, о чем они, и хочу поэкспериментировать. Ожидайте статью от этих экспериментов 😃.
Этот мем фактически представляет этот эксперимент 😆.
Изображения 24: Изображение взято сneuralnetmemesInstagram
Я приветствую любые отзывы, которые могут улучшить меня и эту статью. Я нахожусь в процессе обучения написанию и изучению глубокого обучения. Я ценю обратную связь, чтобы сделать меня лучше. Обязательно дайте обратную связь в надлежащем порядке 😄.
Увидимся в моей следующей статье!
Источник :https://cdn.pixabay.com/photo/2017/07/10/16/07/thank-you-2490552_1280.png
Посмотрите этот репозиторий GitHub:
haryoa / DCGAN-Anime
Самостоятельный проект по созданию аниме лица с использованием DCGAN. Внесите свой вклад в развитие haryoa / DCGAN-Anime, создав аккаунт на…
github.com
В настоящее время я предоставляю только IPython Notebook для обучения GAN с нуля. Обратите внимание, что если модель не выводит изображения в форме лица примерно за 200 итераций, перезапустите тренировку (запустите из ‘Создать модель‘ раздел).
Позже я создам тетрадь для игровых площадок для экспериментов по манипулированию скрытыми переменными.
Deep Learning — Генеративная Состязательная Сеть (GAN)
В этом посте мы разберем Генеративные Состязательные Сети (GAN). Будем сравнивать генеративное и дискриминационное …
medium.com
БлагодарностьРену Хандельвалза отличную статью.
https://www.cs.toronto.edu/~duvenaud/courses/csc2541/slides/gan-foundations.pdf
https://github.com/fchollet/deep-learning-with-python-notebooks
От ГАНА до ГУГА
Этот пост объясняет математику модели генеративной сети состязаний (GAN) и почему это трудно обучить …
lilianweng.github.io
https://arxiv.org/pdf/1511.06434.pdf
GAN — Почему так сложно тренировать Генеративные Состязательные Сети!
Легче распознать картину Моне, чем нарисовать ее. Генеративные модели (создание данных) считаются много …
medium.com
БлагодарностьДжонатан Хуэйза отличную статью.
Оригинальная статья
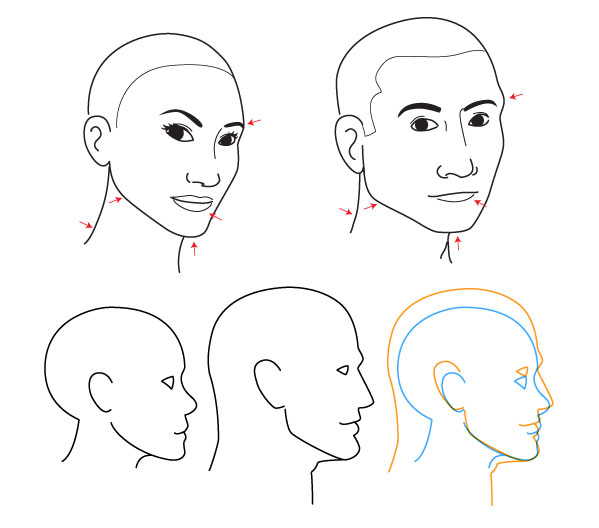
Как нарисовать лицо
В этом уроке мы рассмотрим, как нарисовать лицо, и рассмотрим несколько подходов. Мы начнем с изучения процесса рисования лица спереди. В этой серии шагов мы рассмотрим общее расположение черт лица и изучим несколько пропорциональных сравнений, которые вы можете использовать, чтобы убедиться, что ваши черты лица находятся в правильном месте.
Многие люди делают ошибки при рисовании лиц, потому что не полностью понимают пропорции лица.Пропорция относится к соотношению размеров и размещения между одним объектом и другим.
Существует множество формул, которые можно адаптировать, чтобы нарисовать черты лица в правильном месте. Есть простой подход — тот, который я изучил впервые, и он отлично подходит для новичков. Затем есть более сложный подход с использованием иллюстратора, рекомендаций Эндрю Лумиса.
Как нарисовать лицо спереди — шаг за шагом
Сначала мы обсудим подход Лумиса, который является более сложным, но более точным.Если вы обнаружите, что этот подход немного сложен для вас, вы можете перейти к более простому подходу ниже по странице. Помните, что в любом случае цель состоит в том, чтобы создать убедительный рисунок лица, поэтому любой подход, который вы выберете, подойдет.
Шаг 1. Нарисуйте круг и крест
Сначала мы нарисуем круг с двумя пересекающимися линиями, которые соединяются прямо в центре. Круг представляет собой верхнюю часть головы. Мы будем использовать пересекающиеся линии, чтобы определить расположение черт лица.
Шаг 2. Нарисуйте квадрат внутри круга
Затем мы нарисуем квадрат, каждый угол которого соприкасается с кругом. Этот квадрат в конечном итоге будет представлять края лица. Верхняя линия со временем станет нижней линией роста волос. Нижняя линия станет линией носа, а центральная линия станет линией бровей.
Шаг 3 — Нарисуйте подбородок
Теперь измерим расстояние от центральной линии до нижней линии.Для этого можно использовать карандаш. От нижней линии квадрата используйте это измерение, чтобы отметить положение нижней части подбородка. Затем нарисуйте края подбородка с каждой стороны квадрата, чтобы они соединились в отмеченном месте.
Шаг 4 — Найдите глаза
Теперь у нас есть основная структура формы лица. Теперь мы найдем глаза. Мы можем использовать высоту головы, чтобы определить расположение глаз на лице.Глаза обычно находятся на линии в центре головы.
Линия бровей представлена центральной линией, которую мы нарисовали на первом этапе. Итак, мы знаем, что глаза должны находиться чуть ниже этой линии, в центре головы. Здесь мы можем провести линию для «линии глаз».
Шаг 5 — Рисуем глаза
Теперь, когда мы знаем, где расположены наши глаза на лице, мы можем их нарисовать. Следует иметь в виду еще одно измерение. Также следует учитывать ширину глаз.Ширина головы от уха до уха обычно равна длине пяти «глаз». Это означает, что если мы хотим нарисовать глаза с точными пропорциями, нам нужно нарисовать их так, чтобы они соответствовали этому приблизительному размеру.
В этом уроке мы сосредоточимся только на рисовании лица, но если вам нужны дополнительные инструкции по рисованию глаз, взгляните на эти уроки …
Шаг 6 — Найдите и нарисуйте нос
Спускаясь по лицу, нарисуем нос.Низ носа можно найти на нижней линии квадрата, который мы нарисовали на втором шаге. Ширина носа варьируется от человека к человеку, но обычно такая же ширина, как внутренние уголки глаз.
Может быть полезно провести две светлые линии вниз от внутренних углов глаз, чтобы определить ширину носа.
Нужна небольшая помощь с рисованием носа? Взгляните на эти уроки …
Шаг 7 — Найдите и нарисуйте рот
Мы находим рот немного выше, чем на полпути между нижней частью носа и подбородком.Конечно, это измерение варьируется от человека к человеку. Мы можем нарисовать линию, чтобы обозначить положение рта.
Мы можем использовать глаза, чтобы определить ширину рта. Углы рта обычно совпадают с внутренними краями зрачков. Может быть полезно провести светлые линии от зрачков до «линии рта».
Хотите инструкции по рисованию рта? Взгляните на эти уроки …
Шаг 8 — Нарисуйте уши
Далее нарисуем уши.Здесь мы снова можем использовать расположение черт лица, чтобы помочь нам определить расположение ушей. Верх ушей обычно совпадает с линией бровей, а низ ушей совпадает с линией носа.
Имейте в виду, что уши выходят из головы и слегка поднимаются вверх. Это означает, что уши будут выходить наружу от головы, около линии глаз.
Для этого урока мы набросали только пару ушей.Если вы хотите поближе познакомиться с рисованием уха, ознакомьтесь с этим уроком …
Шаг 9 — Нарисуйте линию волос
Теперь нарисуем линию роста волос. Если вы рисуете кого-то с длинными волосами, которые перекрывают лоб, линия роста волос может быть не видна, но все же важно знать, где она расположена. Линия роста волос находится на верхнем крае квадрата, который мы нарисовали на втором шаге.
Прически сильно различаются от человека к человеку. В этом примере мы нарисуем узор пика вдовы.
Шаг 10 — Нарисуйте волосы
Теперь, когда у нас есть линия роста волос, мы можем нарисовать волосы. Более короткие волосы лишь немного выступают за макушку, в то время как более длинные или густые волосы могут немного выпирать. Однако в обоих случаях волосы выходят за пределы головы, и их не следует рисовать прямо на голове.
Хотите больше инструкций по рисованию волос? Посмотрите этот урок …
Шаг 11 — Добавьте шею
Теперь нам нужно добавить шею к нашей плавающей голове.Большинство начинающих художников склонны делать шею слишком узкой. Вообще говоря, шея идет вниз от ушей. У самок шеи немного тоньше, а у самцов шире.
Чтобы нарисовать шею, просто протянем две линии вниз от нижней части ушей.
Как нарисовать лицо сбоку (профиль)
Если вы хотите нарисовать лицо сбоку или в профиль, применяются те же пропорциональные измерения.Мы просто изменим расположение черт лица, расположив их сбоку от головы.
Фактически, мы можем начать процесс точно так же — начиная с круга с пересекающимися линиями.
Шаг 1. Нарисуйте круг, квадрат и пересекающиеся линии
Мы начнем так же, как и раньше, с рисования круга, двух пересекающихся линий и квадрата, который соприкасается с кругом во всех четырех углах.
Здесь снова верхняя линия нашего квадрата станет линией роста волос.Средняя линия станет линией бровей, а нижняя линия станет линией носа.
Шаг 2 — Проведите линию от макушки до подбородка
Далее отметим расположение нижней части подбородка. Мы можем измерить расстояние от центра квадрата до низа и использовать это измерение, чтобы отметить нижнюю часть подбородка.
Отметив подбородок, нарисуем передний край лица. В этом случае наш объект смотрит влево, поэтому мы проведем изогнутую линию вниз от макушки до нижней части подбородка.
Шаг 3 — Добавьте линию от нижней части подбородка к центру квадрата
Затем мы проведем линию от нижней части подбородка до центральной точки в нижней части квадрата. Эта линия представляет линию подбородка. В большинстве случаев эта линия будет слегка изгибаться.
Шаг 4 — Определите расположение глаз
Теперь мы измерим расстояние до центра головы и проведем линию, представляющую линию глаз. Опять же, эту линию следует провести прямо под линией бровей.
Мы также можем использовать круг, который мы нарисовали с нижней частью квадрата, чтобы нарисовать заднюю часть головы. Подумайте о структуре черепа здесь, когда вы рисуете эту линию.
Шаг 5 — Нарисуйте черты лица и добавьте тени
Теперь, когда у нас есть представление о расположении черт лица, мы можем нарисовать их, используя контурные линии. Мы также добавим здесь немного затенения, чтобы лицо приобрело ощущение формы.
Обратите внимание, как глаза отведены от переднего края лица и как губы и рот отступают по диагонали к шее.
Шаг 6 — Нарисуйте ухо на стороне лица
Мы можем использовать нашу центральную линию, линию носа и линию глаз, чтобы нарисовать ухо сбоку от лица. Поскольку наш объект смотрит влево, большая часть уха будет находиться справа от центральной линии.
Как мы обсуждали ранее, линия уха начинается с линии глаз, продолжается до линии бровей, а затем изгибается вниз, касаясь линии носа.
На этом этапе мы также нарисуем контурную линию для внешнего края волос и пару контурных линий для шеи.
Шаг 7 — Добавьте волосы
Мы сохраним прическу в соответствии с нашим первым рисунком и нарисуем линию роста волос. В этом случае линия тянется назад, прежде чем добраться до ушей.
Мы также добавим несколько штрихов, чтобы придать волосам форму.
Подводя итоги подхода Эндрю Лумиса к рисованию лица
(Некоторые из следующих ссылок являются партнерскими ссылками, что означает, что мы получаем небольшую комиссию, если вы совершаете покупку без дополнительных затрат для вас.)
Эндрю Лумис известен за его пошаговый подход к рисованию голов. Как мы уже говорили выше, его подход делит голову на управляемые геометрические формы. Каждый элемент на грани имеет определенное местоположение относительно геометрической конфигурации, установленной на ранних этапах процесса рисования. Поскольку этот метод настолько точен, его отлично использовать для рисования головы из воображения.
Но этот подход не ограничивается рисованием лиц из воображения. Это также работает при рисовании лица по наблюдениям.Мы просто должны иметь в виду, что каждый человек индивидуален, и изменения этих пропорций будут заметны.
Вот взгляд на лицо и голову, нарисованные из воображения с использованием подхода Лумиса в сочетании с более простым подходом, который мы обсудим чуть ниже на этой странице. Все отношения и пропорции определяются обсуждаемыми руководящими принципами.
Чтобы узнать больше о методе Лумиса для рисования голов, ознакомьтесь с Модулем 4 курса «Умное рисование портретов» или вы можете ознакомиться с его книгой здесь.
.
Простой подход к рисованию лица
Некоторым может показаться, что метод Лумиса немного неудобен для рисования. К счастью, есть более простой подход. Этот подход заимствует идеи из метода Лумиса, но упрощает несколько шагов. Эта формула поможет вам увидеть и сравнить. На каждом этапе формулы анализируйте каждую функцию и нарисуйте то, что вы видите. В результате вы получите репрезентативный портрет человека, которого вы рисуете, со всеми функциями в нужном месте.
Рисование портрета очень похоже на рисование любого другого предмета. Вы должны внимательно наблюдать за предметом, чтобы его точно нарисовать. Конечно, рисование портрета особенно тонко, потому что цель — сделать портрет максимально похожим на объект.
Если вы знаете этого человека, то давление, чтобы добиться точности, может быть устрашающим. Но каждый художник, независимо от уровня его мастерства, должен набраться духа. Даже самые опытные и известные художники-портретисты сталкиваются с проблемами.Рассмотрим эти две цитаты одного из лучших портретистов всех времен Джона Сингера Сарджента …
«Каждый раз, когда пишу портрет, я теряю друга».
«Портрет — это картина, на которой что-то не так с ртом».
Большинство из нас понимают обе эти цитаты. Когда мы рисуем или рисуем портрет, мы все чувствовали давление, чтобы он выглядел точно так же, как наш объект, особенно когда этот объект — друг. На некоторых из нас давление настолько велико, что мы вообще избегаем портретов.
Часто бывает трудно определить проблему на портрете. Мы видим, что что-то не так, но поиск решения или исправления может действительно сбить с толку некоторых из нас. Часто сочетание проблем приводит к «не идеальному» портрету. Может, что-то «не так с ртом».
Несмотря на то, что рисование репрезентативного портрета зависит от хорошего наблюдения и точной маркировки, мы все же можем следовать простой процедуре, которая приведет к лучшим результатам в наших попытках.
Теперь давайте посмотрим на более простой подход к рисованию лица.
Я сделал все шаги, чтобы нарисовать лицо с помощью этого более простого подхода, и поместил их в одно изображение. Пошаговые инструкции можно найти под изображением. Вы заметите, что некоторые из шагов такие же, как мы обсуждали ранее, за исключением использования квадрата для определения линии волос, линии бровей и линии носа.
Первый шаг — нарисовать круг, представляющий череп.Затем можно провести линию, чтобы определить длину лица ( Шаг 1 ). Для большинства лиц эта линия должна быть примерно вдвое длиннее исходного круга.
Затем линии проводят от нижней части этой линии до краев круга, создавая форму лица (, шаг 2, ). Отсюда мы можем определить положение черт лица.
Линия «глаз» проходит посередине лица. (Ваши глаза не находятся на лбу, поэтому не поддавайтесь искушению поместить их туда.) Проводится линия, представляющая линию глаз (, шаг 3, ).
Линия «носа» находится посередине линии «глаз» и нижней части подбородка. Что касается пропорций лица, большинство носов заканчиваются на этой линии (, шаг 3, ). Однако из каждого правила есть исключения. У некоторых людей действительно длинные носы, а у некоторых — очень короткие.
Линия рта находится примерно на одной трети пути вниз между линией носа и нижней частью подбородка.Для его местоположения нарисована линия (, шаг 3, ).
Далее мы сконцентрируемся на глазах. Чтобы определить общую ширину глаз, нарисуйте пять овалов поперек линии глаз. Большинство лиц имеют ширину примерно «пять глаз». Очевидно, у людей всего два глаза. «Пять глаз» просто помогают определить ширину глаз (, шаг 4, ).
Как только мы узнаем точную ширину глаз, мы можем нарисовать их в нужном месте ( Шаг 5 ).
Теперь определим ширину носа.У большинства людей ширина носа совпадает с внутренними уголками глаз. Мы можем просто провести две линии вниз от внутренних углов глаз до линии носа, чтобы найти относительную ширину носа (, шаг 6, ).
Как только мы узнаем ширину носа, мы можем нарисовать его на месте ( Шаг 7 ).
Теперь мы можем определить ширину рта. Это измерение варьируется от человека к человеку, но для большинства людей ширина рта совпадает с внутренней частью радужной оболочки или зрачка.Итак, мы просто проведем линию прямо вниз от этого места до линии рта, чтобы найти уголки рта. Мы нарисуем здесь линию, чтобы указать, где верхняя губа встречается с нижней губой (, шаг 8, ).
Затем мы можем нарисовать верхнюю и нижнюю губы, зная, что рот находится в нужном месте ( Шаг 9 ).
Теперь по ушам. Мы продолжим линию глаз, чтобы определить место, где верхняя часть ушей соприкасается с головой. Они немного расширяются вверх и совпадают с линией бровей.Низ ушей удобно совместить с линией носа ( Step 10 ).
Когда у нас есть уши, мы можем добавить брови. Мы будем использовать кончики ушей для сравнения. У большинства людей линия бровей совпадает с кончиками ушей (, шаг 11, ).
Прежде чем заняться волосами, мы добавим шею. Шея идет вниз от ушей. У женщин эта линия немного расширяется внутрь, в результате чего шея становится меньше. Для мужчин эта линия все еще присутствует немного, но в меньшей степени.Это почти прямо вниз от нижней части ушей ( Step 12 ).
Далее добавляется форма волос. В большинстве случаев волосы отходят от верхней части черепа и могут перекрывать части лба (, шаг 13, ).
Наконец, добавлено затенение для создания иллюзии формы ( Step 14 ).
Обзор общего расположения черт лица
- Глаза находятся посередине головы.
- Углы внутренней части глаз обычно совпадают с краями носа.
- Линия «рта» находится примерно на одну треть ниже линии «носа» и нижней части подбородка. Эта линия показывает, где верхняя губа встречается с нижней.
- Внутренние части зрачков или радужки обычно совпадают с углами рта.
- Уши обычно находятся между линией «глаз» и «носом», но доходят до линии надбровных дуг.
При рисовании лиц используйте эти стандарты, чтобы помочь вам получить правильные пропорции лица. Помните, вы должны смотреть и изучать свой предмет. Хотя эти стандарты применимы к большинству из нас, они не применимы ко всем из нас.
Знание того, где разместить черты лица, безусловно, важно, но для того, чтобы передать лицо на рисунке, нам также необходимо добавить немного затенения. Затенение — это просто процесс манипулирования значением (темнота или яркость цвета).
Форма лица развита за счет использования значения и тона.Отношения конкретных значений информируют зрителя о местонахождении и силе источника света. В конечном итоге иллюзию формы создает поведение света на голове.
Чтобы лучше понять, как ведет себя свет, мы можем рассмотреть плоскости головы и лица. Разбив лицо на простые плоскости, мы сможем лучше понять, как ведет себя свет.
При штриховке полезно думать о голове как о плоских плоскостях. Мы можем видеть эти самолеты, проиллюстрированные ниже…
Плоскости лица меняют направление в пространстве. Эти изменения направления дают разные значения в зависимости от местоположения и силы источника света. В большинстве случаев источник света исходит сверху. Это создает области более темного тона в местах, которые отступают, и более светлые в местах, которые выступают.
Это означает, что углубления вокруг глаз, под носом, нижней губой и подбородком в основном заштрихованы более темными оттенками. Выступающие области, такие как нос, скулы, подбородок и нижняя губа, состоят в основном из более светлых оттенков.
Большинство лиц будут иметь плавные переходы или переходы от светлого к темному. Создание плавных переходов в значениях важно для передачи текстуры кожи.
Ваш подход к штриховке лица будет зависеть от средства, которое вы используете для рисования лица. Для графита или карандаша вы можете просто отрегулировать силу давления, которое вы оказываете на карандаш. Для очень плавных или тонких переходов вы можете использовать растушевку.
Понятие затенения очень широкое.Если вам нужна инструкция по штриховке, взгляните на эти уроки …
Заключение
Рисуя портрет, мы должны помнить, что не существует универсального решения, подходящего для всех. От одного человека к другому будут небольшие пропорциональные различия. Мы можем использовать методы, рассмотренные в этом уроке, чтобы лучше понять расположение черт лица. Но если мы хотим, чтобы наши портретные рисунки отражали сходство человека, мы должны полагаться на наблюдение, чтобы уловить все нюансы.
Теперь, когда вы знаете, как рисовать лицо и расположение черт лица, вы можете нарисовать кого угодно. Просто помните, знания — это только часть этого. Вы должны практиковаться, чтобы увидеть наилучшие результаты с вашими рисунками.
Распознавание лиц | Electronic Frontier Foundation
Распознавание лиц — это метод идентификации или проверки личности человека по его лицу. Системы распознавания лиц можно использовать для идентификации людей на фотографиях, видео или в режиме реального времени.Правоохранительные органы могут также использовать мобильные устройства для идентификации людей во время остановок полиции.
Но данные распознавания лиц могут быть подвержены ошибкам, что может повлечь за собой причастность людей к преступлениям, которых они не совершали. Программное обеспечение для распознавания лиц особенно плохо распознает афроамериканцев и другие этнические меньшинства, женщин и молодых людей, часто неверно идентифицируя или не идентифицируя их, что оказывает несопоставимое влияние на определенные группы.
Кроме того, распознавание лиц использовалось для нацеливания на людей, использующих защищенную речь.В ближайшем будущем технология распознавания лиц, вероятно, станет более распространенной. Его можно использовать для отслеживания передвижения людей по миру, как автоматические считыватели номерных знаков, отслеживающие транспортные средства по номерам. Распознавание лиц в реальном времени уже используется в других странах и даже на спортивных мероприятиях в США.
Как работает распознавание лиц
Источник: Министерство транспорта штата Айова
Системы распознавания лиц используют компьютерные алгоритмы для выделения конкретных отличительных деталей на лице человека.Эти детали, такие как расстояние между глазами или форма подбородка, затем преобразуются в математическое представление и сравниваются с данными о других лицах, собранными в базе данных распознавания лиц. Данные о конкретном лице часто называют шаблоном лица и отличаются от фотографии, потому что он предназначен только для включения определенных деталей, которые можно использовать, чтобы отличить одно лицо от другого.
Некоторые системы распознавания лиц вместо того, чтобы точно идентифицировать неизвестного человека, предназначены для расчета вероятностного соответствия между неизвестным человеком и конкретными шаблонами лиц, хранящимися в базе данных.Эти системы будут предлагать несколько потенциальных совпадений, ранжированных в порядке вероятности правильной идентификации, вместо того, чтобы просто возвращать один результат.
Системы распознавания лиц
различаются по своей способности распознавать людей в сложных условиях, таких как плохое освещение, низкое разрешение изображения и неоптимальный угол обзора (например, на фотографии, сделанной сверху и смотрящей на неизвестного человека сверху вниз).
Когда дело доходит до ошибок, необходимо понимать два ключевых понятия:
«Ложноотрицательный» — это когда системе распознавания лиц не удается сопоставить лицо человека с изображением, которое фактически содержится в базе данных.Другими словами, система ошибочно вернет нулевой результат в ответ на запрос.
«Ложноположительный результат» — это когда система распознавания лиц сопоставляет лицо человека с изображением в базе данных, но на самом деле это совпадение неверно. Это когда полицейский отправляет изображение «Джо», но система ошибочно сообщает офицеру, что это «Джек».
При исследовании системы распознавания лиц важно внимательно посмотреть на частоту «ложных срабатываний» и «ложных отрицательных результатов», поскольку почти всегда существует компромисс.Например, если вы используете распознавание лиц для разблокировки телефона, лучше, если система не сможет идентифицировать вас несколько раз (ложноотрицательный результат), чем система может ошибочно идентифицировать других людей как вас и позволить этим людям разблокировать ваш телефон. (ложно положительный). Если результатом ошибочной идентификации является то, что невиновный человек попадает в тюрьму (например, ошибочная идентификация в базе данных фотографий), тогда система должна быть спроектирована так, чтобы иметь как можно меньше ложных срабатываний.
Как правоохранительные органы используют распознавание лиц
Источник: Министерство транспорта штата Аризона
Правоохранительные органы все чаще используют распознавание лиц в повседневной работе полиции.Полиция собирает фотографии задержанных и сравнивает их с местными, государственными и федеральными базами данных распознавания лиц. После того, как фотография задержанного будет сделана, фотография будет сохранена в одной или нескольких базах данных и будет сканироваться каждый раз, когда полиция будет проводить очередной обыск.
Затем правоохранительные органы могут запросить эти обширные базы данных фотографий, чтобы идентифицировать людей на фотографиях, сделанных из социальных сетей, камер видеонаблюдения, камер дорожного движения, или даже на фотографиях, сделанных ими в полевых условиях. Лица также можно сравнивать в режиме реального времени с «горячими списками» людей, подозреваемых в незаконной деятельности.
Мобильное распознавание лиц позволяет офицерам использовать смартфоны, планшеты или другие портативные устройства, чтобы сфотографировать водителя или пешехода в поле и немедленно сравнить эту фотографию с одной или несколькими базами данных распознавания лиц, чтобы попытаться идентифицировать.
Распознавание лиц использовалось в аэропортах, на пограничных переходах и во время таких мероприятий, как Олимпийские игры. Распознавание лиц также может использоваться в частных помещениях, таких как магазины и спортивные стадионы, но к распознаванию лиц в частном секторе могут применяться другие правила.
Поддержку такого использования восстановления лица поддерживают множество баз данных на местном, государственном и федеральном уровнях. По оценкам, 25% или более всех государственных и местных правоохранительных органов в США могут выполнять поиск по распознаванию лиц в своих базах данных или в базах данных другого агентства.
По данным журнала «Управляющая компания», по состоянию на 2015 год не менее 39 штатов использовали программное обеспечение для распознавания лиц со своими базами данных Департамента транспортных средств (DMV) для выявления мошенничества. В 2013 году газета Washington Post сообщила, что 26 из этих штатов разрешают правоохранительным органам осуществлять поиск или запрашивать поиск в базах данных водительских прав, однако, вероятно, со временем это число увеличилось.
Базы данных также находятся на локальном уровне, и эти базы данных могут быть очень большими. Например, офис шерифа округа Пинеллас во Флориде может иметь одну из крупнейших местных баз данных по анализу лиц. Согласно исследованию Джорджтаунского университета, база данных просматривается около 8000 раз в месяц более чем 240 агентствами.
У федерального правительства есть несколько систем распознавания лиц, но наиболее важной базой данных для правоохранительных органов является база данных идентификации следующего поколения ФБР, которая содержит более 30 миллионов записей распознавания лиц.ФБР разрешает государственным и местным агентствам «отключать» доступ к этой базе данных, что означает, что ни один человек на федеральном уровне не проверяет отдельные поиски. В свою очередь, штаты разрешают ФБР доступ к своим собственным базам данных по распознаванию лиц преступников.
FBI также имеет команду сотрудников, занимающихся только поиском по распознаванию лиц, которые называются Службы анализа, сравнения и оценки лиц («FACE»). ФБР может получить доступ к более чем 400 миллионам фотографий не криминального характера из государственных департаментов и государственного департамента, а также из 16 U.В штатах С. разрешен доступ FACE к водительским правам и фотографиям на удостоверениях личности.
Учитывая большое количество баз данных DMV, использующих распознавание лиц, и количество американцев, чьи фотографии находятся в базе данных Государственного департамента о держателях паспортов и виз США, Джорджтаунский университет оценил, что почти половина всех взрослых американцев были включены по крайней мере в одну, если не больше баз данных распознавания лиц.
Кто продает распознавание лиц
MorphoTrust, дочерняя компания Idemia (ранее известная как OT-Morpho или Safran), является одним из крупнейших поставщиков средств распознавания лиц и других технологий биометрической идентификации в США.Он разработал системы для DMV штата, федеральных и государственных правоохранительных органов, пограничного контроля и аэропортов (включая TSA PreCheck), а также государственного департамента. Среди других распространенных поставщиков — 3M, Cognitec, DataWorks Plus, Dynamic Imaging Systems, FaceFirst и NEC Global.
Угрозы, связанные с распознаванием лиц
Данные о распознавании лиц легко собирать правоохранительными органами, но их трудно избежать. Лица постоянно находятся на виду, но, в отличие от паролей, люди не могут легко изменить свое лицо.Мы наблюдаем рост обмена информацией между агентствами. Камеры становятся все более мощными, а технологии быстро совершенствуются.
Данные распознавания лиц часто получают из фотографий, сделанных после ареста, прежде чем судья когда-либо сможет определить вину или невиновность. Фотоснимки часто никогда не удаляются из базы данных, даже если против задержанных никогда не выдвигались обвинения.
Несмотря на повсеместное распространение распознавания лиц и совершенствование технологий, данные распознавания лиц подвержены ошибкам.Фактически, ФБР признало в своей оценке воздействия на конфиденциальность, что его система «может быть недостаточно надежной, чтобы точно определять местонахождение других фотографий того же имени, что приводит к увеличению процента ошибочных идентификаций». Хотя ФБР заявляет, что его система может найти истинного кандидата в топ-50 профилей в 85% случаев, это только в том случае, когда настоящий кандидат присутствует в галерее. Если кандидата нет в галерее, вполне возможно, что система все равно выдаст одно или несколько потенциальных совпадений, давая ложноположительные результаты.Эти люди — не кандидаты — могут стать подозреваемыми в преступлениях, которых они не совершали. Такая неточная система перекладывает традиционное бремя доказывания с правительства и заставляет людей пытаться доказать свою невиновность.
Распознавание лиц ухудшается по мере увеличения количества людей в базе данных. Это потому, что очень многие люди в мире похожи друг на друга. По мере увеличения вероятности появления похожих лиц точность совпадения снижается.
Программа распознавания лиц
особенно плохо распознает афроамериканцев.Исследование [.pdf] 2012 года, проведенное в соавторстве с ФБР, показало, что показатели точности для афроамериканцев были ниже, чем для других демографических групп. Программное обеспечение для распознавания лиц также чаще неверно идентифицирует другие этнические меньшинства, молодых людей и женщин. Криминальные базы данных включают непропорционально большое количество афроамериканцев, латиноамериканцев и иммигрантов, отчасти из-за расовой предвзятости полиции. Поэтому использование технологии распознавания лиц оказывает разное влияние на цветных людей.
Некоторые утверждают, что резервная идентификация человека (человека, который проверяет идентификацию компьютера) может противодействовать ложным срабатываниям.Однако исследования показывают, что, если людям не хватает специальной подготовки, они примерно в половине случаев принимают неправильные решения о том, подходит ли фотография кандидата. К сожалению, немногие системы имеют специализированный анализ персонала и сужают потенциальные совпадения.
Распознавание лиц можно использовать для нацеливания на людей, использующих защищенную речь. Например, во время протестов вокруг смерти Фредди Грея полицейское управление Балтимора опубликовало фотографии в социальных сетях с помощью распознавания лиц, чтобы идентифицировать протестующих и арестовать их.Из 52 агентств, проанализированных в отчете Джорджтаунского центра конфиденциальности и технологий, только одно агентство, Бюро уголовных расследований штата Огайо, имеет политику распознавания лиц, прямо запрещающую использование этой технологии для отслеживания лиц, причастных к защите свободы слова.
Немногие системы распознавания лиц проверяются на предмет ненадлежащего использования. Из 52 агентств, опрошенных Джорджтауном, которые признали использование распознавания лиц, менее 10% имели общедоступную политику использования. Только два агентства (департамент полиции Сан-Франциско и служба 911 Саут-Саунд в Сиэтле) ограничивают покупку технологий теми, которые соответствуют определенным порогам точности.Только одна — полиция штата Мичиган — предоставляет документацию о процессе аудита.
Существует несколько мер по защите обычных американцев от неправомерного использования технологии распознавания лиц. В целом агентства не требуют ордеров, а многие даже не требуют от правоохранительных органов подозревать кого-либо в совершении преступления, прежде чем использовать распознавание лиц для их идентификации.
Закон штата Иллинойс о конфиденциальности биометрической информации требует уведомления и согласия перед частным использованием технологии распознавания лиц.Однако это касается только компаний, а не правоохранительных органов.
Работа EFF по распознаванию лиц
% 3Ciframe% 20allowfullscreen% 3D% 22% 22% 20src% 3D% 22https% 3A% 2F% 2Fwww.youtube-nocookie.com% 2Fembed% 2FK_2Uww_gZio% 3Frel% 3D0% 26autoplay% 3D1% 26mutewidth% 3D1% 22% 20% 20 3D% 22560% 22% 20height% 3D% 22315% 22% 20frameborder% 3D% 220% 22% 20allow% 3D% 22autoplay% 22% 3E% 3C% 2Fiframe% 3E
Информация о конфиденциальности.
Эта вставка будет обслуживать контент из youtube-nocookie.com
Мы поддерживаем серьезные ограничения на использование распознавания лиц как государственными, так и частными компаниями. Мы свидетельствовали о технологии распознавания лиц в Подкомитете Сената по конфиденциальности, технологиям и законодательству, а также в Комитете Палаты представителей по надзору и правительственным слушаниям по реформе использования правоохранительными органами технологии распознавания лиц. Мы также участвовали в многостороннем процессе распознавания лиц NTIA, но вышли из него вместе с другими НПО, когда компании не могли взять на себя значимые ограничения на использование распознавания лиц.
Мы постоянно подавали запросы в публичные записи для получения ранее секретной информации о системах распознавания лиц. Мы даже подали в суд на ФБР за доступ к его записям распознавания лиц.
В 2015 году EFF и MuckRock запустили краудсорсинговую кампанию для запроса информации о различных мобильных биометрических технологиях, приобретенных правоохранительными органами по всей стране. Вместе с ACLU Миннесоты мы подали записку amicus с требованием опубликовать электронные письма, касающиеся программы распознавания лиц в офисе шерифа округа Хеннепин, которые были запрошены одним местным участником проекта.
Судебные дела EFF
EFF против Министерства юстиции США
Тони Вебстер против офиса шерифа округа Хеннепин и округа Хеннепин
Для получения дополнительной информации
The Perpetual Line-Up (Джорджтаунский юридический центр по вопросам конфиденциальности и технологий)
Технология распознавания лиц: ФБР должно лучше обеспечивать конфиденциальность и точность (Счетная палата правительства)
Калифорнийские полицейские используют эти биометрические устройства в полевых условиях (EFF)
Роль демографической информации при распознавании лиц (IEEE)
Группа услуг по оценке воздействия на конфиденциальность для анализа, сравнения и оценки лиц (FACE) (ФБР)
Последнее обновление 24 октября 2017 г.
принципов биоэтики | UW Департамент биоэтики и гуманитарных наук
Автор : Томас Р.McCormick, D.Min., Старший преподаватель кафедры биоэтики и гуманитарных наук, медицинский факультет Вашингтонского университета
Место принципов в биоэтике
Этический выбор, как незначительный, так и серьезный, ежедневно ставит нас перед нами при оказании медицинской помощи людям с различными ценностями, живущим в плюралистическом и многокультурном обществе. Перед лицом такого разнообразия, где мы можем найти руководство по моральным действиям, когда существует путаница или конфликт по поводу того, что следует делать? Такие руководящие принципы должны быть широко приемлемыми среди религиозных и нерелигиозных людей, а также для людей, принадлежащих к разным культурам.Из-за множества переменных, которые существуют в контексте клинических случаев, а также того факта, что в здравоохранении существует несколько этических принципов, которые кажутся применимыми во многих ситуациях, эти принципы не считаются абсолютными, но служат действенным руководством к действию в клинической практике. медицина. Некоторые принципы медицинской этики используются веками. Например, в 4 веке до нашей эры Гиппократ, врач-философ, велел врачам «помогать и не навредить» (Epidemics, 1780).Точно так же соображения уважения к людям и справедливости присутствовали в развитии общества с самых ранних времен. Однако, особенно в отношении этических решений в медицине, в 1979 году Том Бошамп и Джеймс Чилдресс опубликовали первое издание Принципов биомедицинской этики, теперь уже в его седьмом издании (2013 г.), популяризируя использование принципализма в усилиях по разрешению этических проблем в клинической практике. медицина. В том же году в отчете Бельмона (1979) в качестве руководящих принципов для ответственных исследований с участием людей были определены три принципа: уважение к людям, милосердие и справедливость.Таким образом, как в клинической медицине, так и в научных исследованиях обычно считается, что эти принципы могут применяться даже в уникальных обстоятельствах, чтобы дать руководство в раскрытии наших моральных обязанностей в этой ситуации.
Как принципы «применимы» к определенному случаю?
Интуитивно кажется, что принципы, используемые в настоящее время в этике здравоохранения, имеют самоочевидную ценность и имеют четкое применение. Например, мнение о том, что врач «не должен причинять вреда» пациенту, на первый взгляд убедительно для большинства людей.Или идея о том, что врач должен разработать план ухода, предназначенный для обеспечения максимальной «пользы» пациенту с точки зрения других конкурирующих альтернатив, кажется и рациональной, и самоочевидной. Кроме того, в настоящее время принято считать, что перед внедрением плана медицинского обслуживания пациенту должна быть предоставлена возможность сделать осознанный выбор в отношении своего лечения. Наконец, медицинские льготы должны распределяться справедливо, чтобы к людям с аналогичными потребностями и в аналогичных обстоятельствах относились справедливо, что является важной концепцией в свете ограниченных ресурсов, таких как твердые органы, костный мозг, дорогостоящая диагностика, процедуры и лекарства.
Четыре упомянутых здесь принципа не иерархичны, что означает, что ни один принцип обычно не «превосходит» другой. Кто-то может возразить, что мы должны принимать во внимание все вышеперечисленные принципы, когда они применимы к рассматриваемому клиническому случаю. Тем не менее, когда применяются два или более принципа, мы можем обнаружить, что они противоречат друг другу. Например, рассмотрим пациента с диагнозом остро инфицированный аппендикс. Наша медицинская цель должна заключаться в том, чтобы принести пациенту максимальную пользу, показание для немедленной операции.С другой стороны, операция и общая анестезия несут некоторую небольшую степень риска для здорового пациента, и мы обязаны «не навредить» пациенту. Наше рациональное исчисление гласит, что пациент находится в гораздо большей опасности от разрыва аппендикса, если мы не будем действовать, чем от хирургической процедуры и анестезии, если мы быстро приступим к операции. Кроме того, мы готовы проверить эту рабочую гипотезу рациональным дискурсом, полагая, что другие люди, действующие на рациональной основе, согласятся.Таким образом, взвешивание и балансирование потенциальных рисков и выгод становится важным компонентом процесса обоснования при применении принципов.
Другими словами, несмотря на отсутствие других конкурирующих требований, мы обязаны соблюдать каждый из этих принципов (обязанность prima facie). Однако в реальной ситуации мы должны сбалансировать требования этих принципов, определив, какие из них имеют больший вес в конкретном случае. Философ В.Д. Росс утверждает, что обязанности prima facie всегда имеют обязательную силу, если только они не противоречат более строгим или более строгим обязанностям.Фактический долг морального человека определяется путем взвешивания и уравновешивания всех конкурирующих обязанностей prima facie в каждом конкретном случае (Frankena, 1973). Поскольку принципы не содержат содержания, применение принципа становится предметом внимания благодаря пониманию уникальных особенностей и фактов, которые обеспечивают контекст для дела. Следовательно, получение актуальных и точных фактов является важным компонентом этого подхода к принятию решений.
Каковы основные принципы медицинской этики?
Четыре общепринятых принципа этики здравоохранения, взятые из работы Бошан и Чилдресс (2008), включают:
- Принцип уважения автономии,
- Принцип непричинения вреда,
- Принцип милосердия и
- Принцип справедливости.
1. Уважение к автономии
Любое понятие морального принятия решений предполагает, что рациональные агенты участвуют в принятии информированных и добровольных решений. При принятии медицинских решений наше уважение к автономии пациента, в просторечии, будет означать, что пациент обладает способностью действовать намеренно, с пониманием и без контролирующих влияний, которые могли бы смягчить свободное и добровольное действие. Этот принцип лежит в основе практики «информированного согласия» в отношениях между врачом и пациентом в отношении медицинского обслуживания.(См. Также Информированное согласие.)
Случай 1
I С первого взгляда мы всегда должны уважать независимость пациента. Такое уважение — это не просто вопрос отношения, но способ действовать таким образом, чтобы признать и даже способствовать автономным действиям пациента. Автономное лицо может свободно выбирать ценности, верность или системы религиозных убеждений, которые ограничивают другие свободы этого человека. Например, Свидетели Иеговы считают, что принимать переливание крови неправильно.Следовательно, в опасной для жизни ситуации, когда для спасения жизни пациента требуется переливание крови, пациент должен быть проинформирован об этом. Последствия отказа от переливания крови должны быть понятны пациенту, который рискует умереть от кровопотери. Желая «принести пользу» пациенту, врач может сильно захотеть сделать переливание крови, полагая, что это явная «медицинская помощь». выгода.» При надлежащем и сострадательном информировании конкретный пациент может выбрать, согласиться ли на переливание крови в соответствии с сильным желанием жить, или отказаться от переливания крови, отдав больший приоритет своим религиозным убеждениям о неправильности переливания крови, вплоть до принятия смерти как предсказуемого исхода.Этот процесс общения должен быть сострадательным и уважительным к уникальным ценностям пациента, даже если они отличаются от стандартных целей биомедицины.
Обсуждение
При анализе вышеупомянутого случая врач имел обязанность prima facie уважать самостоятельный выбор пациента, а также обязанность prima facie избегать причинения вреда и оказывать медицинскую помощь. В этом случае, опираясь на общественную практику и положения закона о свободном исповедании религии, врач уделял больше внимания уважению автономии пациента, чем другим обязанностям.Однако некоторые специалисты по этике утверждают, что в отношении выбора пациента не получать кровь, также применяется принцип непричинения вреда, который должен интерпретироваться в свете системы убеждений пациента о природе вреда, в данном случае духовного вреда. Напротив, в экстренных случаях, если рассматриваемый пациент оказывается десятилетним ребенком, а родители отказывают в разрешении на переливание жизненно важной крови, в штате Вашингтон и других штатах также имеется преимущественная юридическая сила для отмены желание родителей путем обращения к судье суда по делам несовершеннолетних, который уполномочен государством защищать жизнь своих граждан, особенно несовершеннолетних, до тех пор, пока они не достигнут совершеннолетия, и может делать такой выбор независимо.Таким образом, в случае уязвимого несовершеннолетнего ребенка принцип избежания смертельного вреда и принцип предоставления медицинской помощи, которая может вернуть ребенку здоровье и жизнь, будут иметь приоритет перед автономией родителей ребенка, поскольку суррогатные лица, принимающие решения (McCormick, 2008). (См. «Принятие решения родителями»)
2. Принцип непричинения вреда
Принцип непричинения вреда требует от нас, чтобы мы не причиняли преднамеренного вреда или вреда пациенту посредством действий или бездействия.Говоря простым языком, мы считаем халатным, если один по неосторожности или необоснованно рискует причинить вред другому. Обеспечение надлежащего стандарта ухода, позволяющего избежать или минимизировать риск причинения вреда, поддерживается не только нашими общепринятыми моральными убеждениями, но и законами общества (см. Закон и медицинская этика). Этот принцип подтверждает необходимость медицинской компетентности. Понятно, что возможны врачебные ошибки; однако этот принцип формулирует фундаментальное обязательство со стороны специалистов здравоохранения защищать своих пациентов от вреда.
Случай 2
В процессе ухода за пациентами бывают ситуации, в которых некоторый вид вреда кажется неизбежным, и мы обычно морально обязаны выбирать меньшее из двух зол, хотя меньшее из зол может определяться обстоятельства. Например, большинство из них захотят испытать некоторую боль, если рассматриваемая процедура продлит жизнь. Однако в других случаях, например, в случае смерти пациента от болезненной карциномы кишечника, пациент может отказаться от СЛР в случае остановки сердца или дыхания, или же пациент может отказаться от поддерживающих жизнь технологий, таких как диализ. или респиратор.Причина такого выбора основана на убеждении пациента, что длительная жизнь с болезненным и изнурительным состоянием хуже смерти, больший вред. В этом случае также важно отметить, что это определение было сделано пациентом, который единственный является авторитетом в интерпретации «большего» или «меньшего» вреда для себя. (См. Отказ от лечения или отказ от поддерживающего жизнь лечения).
Обсуждение
Есть еще одна категория случаев, которая сбивает с толку, поскольку одно действие может иметь два эффекта: один считается хорошим, а другой — плохим.Как наш долг перед принципом непричинения вреда направляет нас в таких случаях? Официальное название принципа, регулирующего эту категорию дел, обычно называют принципом двойного действия. Типичным примером может быть вопрос о том, как лучше всего лечить беременную женщину, у которой недавно диагностирован рак матки. Обычное лечение, удаление матки, считается лечением, спасающим жизнь. Однако эта процедура может привести к смерти плода. Какое действие допустимо с моральной точки зрения или каков наш долг? В этом случае утверждается, что женщина имеет право на самооборону, и действие гистерэктомии направлено на защиту и сохранение ее жизни.Предвидимое непредвиденное последствие (хотя и нежелательное) — смерть плода. К принципу двойного эффекта обычно применяются четыре условия:
- Характер акта. Само действие не должно быть изначально неправильным; это должен быть хороший или, по крайней мере, морально нейтральный поступок.
- Намерение агента. Агент предполагает только хороший эффект, а не плохой эффект, даже если он предусмотрен.
- Различие между средствами и эффектами. Плохой эффект не должен быть средством хорошего эффекта,
- Пропорциональность между хорошим и плохим эффектом.Хороший эффект должен перевешивать дозволенное зло, другими словами, плохой эффект.
(Beauchamp & Childress, 1994, стр. 207)
Читатель может применить эти четыре критерия к вышеупомянутому случаю и обнаружить, что применяется принцип двойного эффекта и четыре условия не нарушаются предписанным планом лечения.
3. Принцип милосердия
Обычное значение этого принципа состоит в том, что поставщики медицинских услуг обязаны приносить пользу пациенту, а также принимать позитивные меры для предотвращения и устранения вреда, причиненного пациенту.Эти обязанности рассматриваются как рациональные и самоочевидные и широко признаются как истинные цели медицины. Этот принцип лежит в основе здравоохранения, подразумевая, что страдающий проситель (пациент) может вступить в отношения с тем, кого общество признало компетентным оказывать медицинскую помощь, веря, что главная цель врача — помочь. цель предоставления пользы может быть применена как к отдельным пациентам, так и на благо общества в целом. Например, хорошее здоровье конкретного пациента — это подходящая цель медицины, а профилактика заболеваний посредством исследований и применение вакцин — та же цель, распространенная на население в целом.
Иногда считают, что непричинение вреда — это постоянная обязанность, то есть никогда не следует причинять вред другому человеку, тогда как благотворительность — это ограниченная обязанность. Врач обязан стремиться к пользе для кого-либо или всех своих пациентов, однако врач также может выбрать, кого допустить в свою практику, и не имеет строгой обязанности оказывать помощь пациентам, не включенным в комиссию. Эта обязанность усложняется, если два пациента обращаются за лечением одновременно. Чтобы решить, кому следует помочь в данный момент, можно использовать некоторые критерии срочности или принцип «первым пришел — первым обслужен».
Случай 3
Один наглядный пример существует в здравоохранении, где принцип благотворительности имеет приоритет над принципом уважения автономии пациента. Этот пример взят из Emergency Medicine. Когда пациент становится недееспособным в результате серьезного несчастного случая или болезни, мы предполагаем, что разумный человек хотел бы, чтобы его лечили агрессивно, и спешим оказать благотворное вмешательство, остановив кровотечение, залечив сломанные или наложив швы на раненых.
Обсуждение
В этой культуре, когда врач действует из доброжелательного духа, обеспечивая благотворное лечение, которое, по мнению врача, отвечает наилучшим интересам пациента, без консультации с пациентом или игнорирования его желаний, это считается быть «патерналистским». Наиболее очевидный случай оправданного патернализма наблюдается в лечении суицидальных пациентов, которые представляют для себя явную опасность. В данном случае обязанность проявлять милосердие требует, чтобы врач вмешался в целях спасения жизни пациента или помещения пациента в защитную среду, полагая, что пациент находится под угрозой и не может действовать в своих интересах в данный момент.Как всегда, обстоятельства дела чрезвычайно важны для того, чтобы сделать вывод о том, что автономия пациента поставлена под угрозу.
4. Принцип справедливости
Справедливость в здравоохранении обычно определяется как форма справедливости или, как однажды сказал Аристотель, «отдавать каждому то, что ему причитается». Это подразумевает справедливое распределение благ в обществе и требует, чтобы мы смотрели на роль прав. Вопрос о справедливости распределения также, по-видимому, зависит от того факта, что некоторых товаров и услуг не хватает, их недостаточно, поэтому необходимо определить справедливые способы распределения ограниченных ресурсов.
Обычно считается, что равные лица должны иметь право на равное обращение. Это подтверждается приложением Medicare, доступным для всех лиц старше 65 лет. Эта категория лиц равна по одному фактору — по возрасту, но выбранные критерии ничего не говорят о потребностях или других значимых факторах, касающихся лиц в этой категории. Фактически, наше общество использует множество факторов в качестве критериев справедливого распределения, включая следующие:
- Каждому равную долю
- Каждому по потребности
- Каждому по усилию
- Каждому по взносу
- Каждому по заслугам
- Каждому согласно свободному рынку
(Beauchamp & Childress, 1994, стр.330)
Джон Роулз (1999) и другие утверждают, что многие из неравенств, с которыми мы сталкиваемся, являются результатом «естественной лотереи» или «социальной лотереи», в которой пострадавший не виноват, поэтому общество должно помогать даже игре поле, предоставляя ресурсы, чтобы помочь преодолеть неблагоприятную ситуацию. Один из самых противоречивых вопросов в современном здравоохранении — это вопрос «кто имеет право на охрану здоровья?». Или, говоря другими словами, возможно, мы как общество хотим быть доброжелательными и справедливыми и обеспечивать достойный минимальный уровень здравоохранения для всех граждан, независимо от их платежеспособности.Medicaid — это также программа, предназначенная для оказания помощи в финансировании медицинского обслуживания малоимущих слоев населения. Тем не менее, во время рецессии тысячи семей, живущих за чертой бедности, были исключены из списков Medicaid в качестве меры экономии. Принцип справедливости — сильная мотивация к реформе нашей системы здравоохранения, чтобы во внимание были приняты потребности всего населения. Требования принципа справедливости должны применяться у постели больного, но также системно в законах и политике общества, которые регулируют доступ населения к медицинской помощи.В этой области еще предстоит проделать большую работу.
Резюме и критика
Четыре принципа, которые в настоящее время действуют в этике здравоохранения, имеют долгую историю в общей морали нашего общества еще до того, как за последние сорок с лишним лет стали широко популярными в качестве руководящих принципов моральных действий в медицинской этике благодаря работе таких специалистов по этике, как Бошам и Чилдресс . Перед лицом морально неоднозначных ситуаций в сфере здравоохранения нюансы их использования были уточнены с помощью бесчисленных приложений.Некоторые специалисты по биоэтике, такие как Бернард Герт и его коллеги (1997), утверждают, что, за исключением отсутствия вреда, эти принципы ошибочны в качестве руководящих принципов моральных действий, поскольку они настолько неспецифичны и, кажется, просто напоминают лицу, принимающему решение, о соображениях, которые следует принять во внимание. . В самом деле, Бошан и Чилдресс не утверждают, что принциплизм обеспечивает общую моральную теорию, но, скорее, они подтверждают полезность этих принципов при размышлении о моральных проблемах и в продвижении к этическому разрешению.Герт также обвиняет в принципиализме неспособность провести различие между моральными правилами и моральными идеалами и, как упоминалось ранее, в том, что не существует согласованного метода разрешения конфликтов, когда два разных принципа противоречат тому, что следует делать. Он утверждает, что его собственный подход, общая мораль, апелляция к рациональному размышлению и открытость для прозрачности и гласности — более полезный подход (Gert, Culver & Clouser, 1997). Кроме того, специалист по биоэтике Альберт Йонсен и его коллеги (2010) утверждают в своей работе, что для того, чтобы строго применять эти принципы в клинических ситуациях, их применимость должна начинаться с контекста конкретного случая.(См. Инструменты биоэтики).
Эта статья представляет собой краткое введение в использование этических принципов в этике здравоохранения. Студенты, изучающие клиническую этику, найдут дополнительную информацию и более глубокий анализ в предлагаемых ниже материалах для чтения.
Список литературы
Бошамп Т., Чилдресс Дж. Принципы биомедицинской этики, 7-е издание. Нью-Йорк: Oxford University Press, 2013.
.
Frankena, WK. Этика, 2-е издание. Энглвуд Клиффс, Нью-Джерси: Прентис-Холл, 1973.
Герт Б., Калвер К.М., Клоузер К.Д., Биоэтика — возвращение к основам. Нью-Йорк: Oxford University Press, 1997.
.
Гиппократ. История эпидемий. Сэмюэл Фарр (пер.) Лондон: Т. Каделл, 1780.
Jonsen A, Siegler M, Winslade W. Ethics, 7-е издание. Нью-Йорк: McGraw-Hill Medical, 2010.
Маккормик, TR. Этические проблемы Свидетелей Иеговы. Периоперационные клиники медсестер 2008; 3 (3): 253-259.
Ролз Дж. Теория справедливости. Кембридж, Массачусетс: Издательство Гарвардского университета, 1999.
Связанные темы обсуждений / Ссылки
Информированное согласие, Принятие решения родителями, Отказ или отмена поддерживающего жизнь лечения, Инструменты биоэтики
Thomas R. McCormick, D Min
Факультет биоэтики и гуманитарных наук
Вашингтонский университет
Можем ли мы прочитать характер человека по изображениям лица?
Физиогномика, бессмысленная наука о чтении характера по внешнему виду лица, имеет долгую историю, первые сохранившиеся документы о ней относятся ко времени Аристотеля.Дарвин почти упустил свой шанс совершить свое историческое путешествие на Beagle из-за своего носа, потому что капитан корабля — пылкий физиономист — не верил, что человек с таким носом будет обладать достаточной решимостью для путешествия. . «Но я думаю, — сухо заметил Дарвин в своей автобиографии, — впоследствии он был вполне удовлетворен тем, что мой нос сказал ложь».
Мы можем подшучивать над идеями физиогномистов, но современная наука о первых впечатлениях показывает, что все мы наивные физиогномисты.Мы формируем мгновенное впечатление о других по их внешнему виду. Чтобы принять решение, достаточно увидеть лицо менее одной десятой секунды. Первое впечатление не только быстрое, но и важное: мы с большей вероятностью будем голосовать за политиков, которые выглядят компетентными; инвестировать в людей, которые выглядят заслуживающими доверия; и назначать более суровые тюремные сроки людям, которые выглядят противоположными. Фейсизм — общая черта общественной жизни.
Современная наука о первых впечатлениях также определила многие стереотипы лица, которые определяют эти впечатления.В последнее десятилетие психологи разработали математические модели, визуализирующие эти стереотипы. С помощью этих моделей мы можем управлять внешним видом лиц, увеличивая или уменьшая их воспринимаемые качества надежности и компетентности по своему желанию. И что еще более важно, мы можем строить и проверять теории о происхождении лицевых стереотипов.
Однако одним из непредвиденных последствий прогресса в этих исследованиях стало возрождение физиогномики. Возможно, наши стереотипы лица — это не просто стереотипы, а истинное окно в характер других.Соответственно, появилось множество исследований, утверждающих, что мы можем различать всевозможные личные вещи о других, такие как их психическое здоровье, политическая и сексуальная ориентация и так далее, только по их лицевым изображениям.
Эти утверждения обычно основаны на выводе о том, что предположения людей, скажем, о сексуальной ориентации лучше случайности. Проблема в том, что эти предположения едва ли лучше случайности и часто менее точны, чем предположения, основанные на более общих знаниях.
Более того, многие из этих исследований основаны на заблуждении, что все изображения лиц одинаково репрезентативны для владельца лица. Хотя это предположение может показаться верным в случае знакомых лиц, которые легко узнать по разным изображениям, оно определенно неверно в случае незнакомых лиц — и по определению первое впечатление связано с незнакомыми лицами. Часто мы не можем сказать, представляют ли два разных изображения одного и того же (незнакомого) человека, и эти изображения могут вызывать совершенно разные впечатления.Следовательно, выбор изображений является критическим моментом при оценке точности первого впечатления.
Подумайте, как предвзятость в выборке изображений может повлиять на выводы о точности первого впечатления. Во многих исследованиях «гейдара» участники угадывают сексуальную ориентацию других людей по изображениям, размещенным на сайтах онлайн-знакомств. В одном из самых первых таких исследований предположения были точными примерно в 58% случаев (при вероятности 50%). Но поскольку мы стратегически выбираем изображения, которые публикуем, чтобы представить себя тем людям, которых мы хотим привлечь, это не нейтральный образец.
Фактически, когда предположения основывались на онлайн-изображениях геев и гетеросексуальных мужчин, размещенных их друзьями (далеко не идеальный контроль), они были точными только в 52 процентах случаев. Такой результат верен не только тогда, когда испытуемые предполагают сексуальную ориентацию. В недавнем исследовании исследователи использовали изображения с сайтов онлайн-знакомств, чтобы проверить, могут ли участники угадать социальный класс, представленный богатством. Участники были точны примерно в 57% случаев. Но когда предположения были основаны на изображениях, сделанных в стандартных условиях, точность упала до 51.5 процентов.
С повсеместным распространением изображений лиц в Интернете исследования, пытающиеся определить нашу «сущность» по этим изображениям, никуда не денутся. В последние несколько лет появилась новая волна исследований искусственного интеллекта (ИИ), пытающихся сделать именно это. Технологический стартап уже предлагает услуги профилирования лиц частным компаниям и правительствам. В прошлом году двое компьютерных ученых опубликовали в Интернете статью, не прошедшую экспертную оценку, в которой утверждалось, что их алгоритм может угадывать преступность людей по одному изображению лица.А недавно престижный журнал принял к публикации статью, в которой утверждалось, что алгоритмы искусственного интеллекта могут определять сексуальную ориентацию по изображениям лиц с удивительной точностью.
Однако те же проблемы, что и в исследованиях на людях, применимы и к исследованиям искусственного интеллекта. Последние используют мощные алгоритмы, которые могут обнаруживать тонкие, но систематические различия между двумя наборами изображений. Но выборка изображений, используемых для обучения алгоритма, так же важна, как и сам алгоритм. В статье о преступности авторы представили несколько изображений «преступников» и «не преступников».«Помимо очевидных различий в выражениях лиц,« преступники »носили футболки, а« непреступники »- костюмы. Мощный алгоритм легко уловил бы эти различия и произвел бы кажущуюся точной классификацию.
Заблуждение, что все изображения лица одинаково репрезентативны для лица владельца, играет еще более тонкими способами в исследованиях искусственного интеллекта, особенно когда утверждается, что алгоритмы измеряют инвариантные черты лица по двумерным изображениям. Расстояние от камеры до головы, параметры камеры, небольшой наклон головы, тонкие выражения и многие другие, очевидно, тривиальные различия влияют на измерение того, что должно быть стабильными морфологическими особенностями.Когда эти различия не контролируются, исследования ИИ просто усиливают наши человеческие предубеждения.
Более того, последствия использования ИИ для «чтения по лицу» морально отвратительны. Старший автор статьи о сексуальной ориентации утверждает, что его главной мотивацией было предупредить ЛГБТ-сообщество о том, что эта технология может нанести им вред, особенно в репрессивных странах. Но в то время как исследование утверждает, что выявляет реальные морфологические различия между геями и натуралами, все, что оно на самом деле показывает, — это то, что алгоритм может идентифицировать открыто гомосексуальных людей по их самопубликованным изображениям — так же, как это могут делать обычные люди.
Это именно то «научное» утверждение, которое может мотивировать репрессивные правительства применять алгоритмы ИИ к изображениям своих граждан. И что мешает им «читать» по этим изображениям интеллект, политическую ориентацию и криминальные наклонности?
Amazon Rekognition — часто задаваемые вопросы
Общий
Вопрос: Что такое Amazon Rekognition?
Amazon Rekognition — это сервис, который упрощает добавление мощных средств визуального анализа в ваши приложения.Rekognition Image позволяет легко создавать мощные приложения для поиска, проверки и систематизации миллионов изображений. Rekognition Video позволяет извлекать контекст на основе движения из сохраненных или потоковых видео и помогает анализировать их.
Rekognition Image — это служба распознавания изображений, которая обнаруживает объекты, сцены и лица; извлекает текст; узнает знаменитостей; и определяет неприемлемый контент на изображениях. Он также позволяет искать и сравнивать лица. Rekognition Image основан на той же проверенной, хорошо масштабируемой технологии глубокого обучения, разработанной специалистами Amazon по компьютерному зрению для ежедневного анализа миллиардов изображений для Prime Photos.
Rekognition Image использует модели глубокой нейронной сети для обнаружения и маркировки тысяч объектов и сцен на ваших изображениях, и мы постоянно добавляем новые метки и функции распознавания лиц в сервис. С Rekognition Image вы платите только за анализируемые изображения и сохраненные метаданные лиц.
Rekognition Video — это служба распознавания видео, которая обнаруживает действия; понимает движение людей в кадре; и распознает объекты, знаменитостей и неприемлемый контент в видеороликах, хранящихся в Amazon S3, и потокового видео в реальном времени от Acuity.Rekognition Video обнаруживает людей и отслеживает их по видео, даже когда их лица не видны или когда весь человек может входить и выходить из сцены. Например, это можно использовать в приложении, которое отправляет уведомление в режиме реального времени, когда кто-то доставляет посылку к вашей двери. Rekognition Video также позволяет индексировать метаданные, такие как объекты, действия, сцены, знаменитости и лица, что упрощает поиск видео.
Вопрос: Что такое глубокое обучение?
Глубокое обучение — это подраздел машинного обучения и важная ветвь искусственного интеллекта.Он направлен на вывод высокоуровневых абстракций из необработанных данных с использованием глубокого графа с несколькими уровнями обработки, состоящими из нескольких линейных и нелинейных преобразований. Глубокое обучение в общих чертах основано на моделях обработки информации и коммуникации в мозге. Глубокое обучение заменяет созданные вручную функции функциями, изученными на основе очень больших объемов аннотированных данных. Обучение происходит путем итеративной оценки сотен тысяч параметров в глубоком графе с помощью эффективных алгоритмов.
Несколько архитектур глубокого обучения, таких как сверточные глубокие нейронные сети (CNN) и рекуррентные нейронные сети, были применены к компьютерному зрению, распознаванию речи, обработке естественного языка и распознаванию звука для получения самых современных результатов при решении различных задач.
Amazon Rekognition является частью семейства сервисов Amazon AI. Сервисы Amazon AI используют глубокое обучение для понимания изображений, преобразования текста в реалистичную речь и создания интуитивно понятных диалоговых текстовых и речевых интерфейсов.
Вопрос: Нужен ли мне опыт глубокого обучения для использования Amazon Rekognition?
Нет. С Amazon Rekognition вам не нужно создавать, поддерживать или обновлять конвейеры глубокого обучения.
Для достижения точных результатов в сложных задачах компьютерного зрения, таких как обнаружение объектов и сцен, анализ лиц и распознавание лиц, системы глубокого обучения должны быть правильно настроены и обучены с огромными объемами размеченных наземных данных.Точный поиск, очистка и маркировка данных — это трудоемкая и дорогостоящая задача. Более того, обучение глубокой нейронной сети требует больших вычислительных ресурсов и часто требует специального оборудования, созданного с использованием графических процессоров (GPU).
Amazon Rekognition полностью управляется и поставляется предварительно обученным для задач распознавания изображений и видео, поэтому вам не нужно тратить свое время и ресурсы на создание конвейера глубокого обучения. Amazon Rekognition продолжает повышать точность своих моделей, опираясь на последние исследования и используя новые данные для обучения.Это позволяет вам сосредоточиться на проектировании и разработке ценных приложений.
Вопрос: Каковы наиболее распространенные варианты использования Amazon Rekognition?
Наиболее распространенные варианты использования Rekognition Image:
- Библиотека изображений с возможностью поиска
- Подтверждение пользователя по лицу
- Анализ настроений
- Распознавание лиц
- Модерация изображения
Наиболее распространенные варианты использования Rekognition Video:
- Индекс поиска видеоархивов
- Простая фильтрация видео для откровенного и непристойного содержания
Вопрос: Как начать работу с Amazon Rekognition?
Если вы еще не зарегистрировались в Amazon Rekognition, вы можете нажать кнопку «Попробовать Amazon Rekognition» на странице Amazon Rekognition и завершить процесс регистрации.У вас должна быть учетная запись Amazon Web Services; если у вас его еще нет, вам будет предложено создать его в процессе регистрации. После регистрации попробуйте Amazon Rekognition со своими изображениями и видео с помощью консоли управления Amazon Rekognition или загрузите SDK Amazon Rekognition, чтобы начать создавать свои собственные приложения. Пожалуйста, обратитесь к нашему пошаговому руководству по началу работы для получения дополнительной информации.
Вопрос: Какие API предлагает Amazon Rekognition?
Amazon Rekognition Image предлагает API-интерфейсы для обнаружения объектов и сцен, обнаружения и анализа лиц, распознавания знаменитостей, обнаружения неприемлемого контента и поиска похожих лиц в коллекции лиц, а также API-интерфейсы для управления ресурсами.Rekognition Image также предлагает API-интерфейсы для сравнения лиц и извлечения текста, в то время как Rekognition Video также предлагает API-интерфейсы для отслеживания людей и управления видео в реальном времени из Acuity. Дополнительные сведения см. В Справочнике по API Amazon Rekognition.
Вопрос: Какие форматы изображений и видео поддерживает Amazon Rekognition?
Amazon Rekognition Image в настоящее время поддерживает форматы изображений JPEG и PNG. Вы можете отправлять изображения как объект S3 или как массив байтов.Операции Amazon Rekognition Video могут анализировать видео, хранящиеся в корзинах Amazon S3. Видео должно быть закодировано с использованием кодека H.264. Поддерживаемые форматы файлов: MPEG-4 и MOV. Кодек — это программное или аппаратное обеспечение, которое сжимает данные для более быстрой доставки и распаковывает полученные данные в их исходную форму. Кодек H.264 обычно используется для записи, сжатия и распространения видеоконтента. Формат видеофайла может содержать один или несколько кодеков. Если ваш видеофайл в формате MOV или MPEG-4 не работает с Rekognition Video, убедитесь, что для кодирования видео используется кодек H.264.
В. Какие размеры файлов можно использовать с Amazon Rekognition?
Amazon Rekognition Image поддерживает файлы изображений размером до 15 МБ при передаче в виде объекта S3 и до 5 МБ при передаче в виде байтового массива. Amazon Rekognition Video поддерживает файлы размером до 10 ГБ и видео продолжительностью до 6 часов при передаче в виде файла S3.
Вопрос: Как разрешение изображения влияет на качество результатов Rekognition Image API?
Amazon Rekognition работает с широким диапазоном разрешений изображений.Для достижения наилучших результатов мы рекомендуем использовать разрешение VGA (640×480) или выше. Уменьшение значения QVGA (320×240) может увеличить вероятность пропуска лиц, объектов или несоответствующего содержимого; хотя Amazon Rekognition принимает изображения размером не менее 80 пикселей в обоих измерениях.
Вопрос: Насколько маленьким может быть объект, чтобы Amazon Rekognition Image мог его обнаружить и проанализировать?
Как правило, убедитесь, что самый маленький объект или лицо на изображении составляет не менее 5% от размера (в пикселях) меньшего размера изображения.Например, если вы работаете с изображением 1600×900, самое маленькое лицо или объект должны иметь размер не менее 45 пикселей в любом измерении.
Вопрос: Как получить доступ к прогнозам Amazon Rekognition для проверки людьми?
Amazon Rekognition напрямую интегрирован с Amazon Augmented AI (Amazon A2I), поэтому вы можете легко перенаправлять прогнозы с низкой достоверностью из Amazon Rekognition Image рецензентам. Используя Amazon Rekognition API для модерации контента или консоль Amazon A2I, вы можете указать условия, при которых Amazon A2I направляет прогнозы проверяющим, которые могут быть либо порогом достоверности, либо процентом случайной выборки.Если вы укажете порог достоверности, Amazon A2I направляет только те прогнозы, которые ниже порога для проверки человеком. Вы можете изменить эти пороговые значения в любое время, чтобы достичь правильного баланса между точностью и экономичностью. В качестве альтернативы, если вы укажете процент выборки, Amazon A2I направит случайную выборку прогнозов для проверки человеком. Это может помочь вам проводить аудит для регулярного контроля точности прогнозов. Amazon A2I также предоставляет обозревателям веб-интерфейс, содержащий все инструкции и инструменты, необходимые для выполнения задач проверки.Для получения дополнительной информации о реализации проверки человеком с помощью Amazon Rekognition посетите веб-страницу Amazon A2I.
Q: Как разрешение видео влияет на качество результатов Rekognition Video API?
Система обучена распознавать лица размером более 32 пикселей (по самому короткому измерению), что соответствует минимальному размеру распознаваемого лица, который варьируется от примерно 1/7 меньшего размера экрана при разрешении QVGA до 1/30. при разрешении HD 1080p.Например, при разрешении VGA пользователи должны ожидать более низкой производительности для лиц размером менее 1/10 экрана меньшего размера.
В. Что еще может повлиять на качество API-интерфейсов Rekognition Video?
Помимо разрешения видео, на качество API могут влиять сильное размытие, быстро движущиеся люди, условия освещения, поза.
Q: Какой пользовательский видеоконтент лучше всего подходит для API-интерфейсов Rekognition Video?
Этот API лучше всего работает с потребительскими и профессиональными видео, снятыми с фронтальным полем зрения в нормальных условиях цвета и освещения.Этот API не тестируется для работы в черно-белом, ИК-диапазоне или в условиях экстремального освещения. Приложениям, чувствительным к ложным срабатываниям, рекомендуется отбрасывать выходные данные с показателем достоверности ниже выбранного (зависящего от приложения) показателя достоверности.
Вопрос: В каких регионах AWS доступен Amazon Rekognition?
Список всех регионов, в которых доступен Amazon Rekognition, см. В таблице регионов AWS.
Визуальный опыт не требуется для развития селективности лица в боковой веретенообразной извилине
Значимость
Здесь мы демонстрируем устойчивую селективность лица в боковой веретенообразной извилине у врожденно слепых участников во время тактильного исследования стимулов, отпечатанных на 3D-принтере, что указывает на то, что ни визуальный опыт, ни входные данные с фовеа, ни визуальные знания не нужны для того, чтобы избирательность лица возникла в его характерном месте.Сходные корреляционные отпечатки фМРТ в покое у отдельных слепых и зрячих участников предполагают роль связи на больших расстояниях в спецификации кортикального локуса избирательности лица.
Abstract
Веретенообразная область лица выборочно реагирует на лица и причинно участвует в восприятии лица. Как избирательность лица у веретенообразной формы возникает в процессе развития и почему она развивается так систематически в одном и том же месте у разных людей? Предпочтительные корковые реакции на лица развиваются в раннем младенчестве, однако данные по центральному вопросу о необходимости визуального опыта с лицами противоречивы.Здесь мы еще раз возвращаемся к этому вопросу, сканируя слепых от рождения людей с помощью фМРТ, пока они тактильно исследовали лица, напечатанные на 3D-принтере, и другие стимулы. Мы обнаружили устойчивые реакции селективного выбора лица в боковой веретенообразной извилине отдельных слепых участников во время тактильного исследования стимулов, что указывает на то, что для возникновения избирательности лица в боковой веретенообразной извилине не требуется ни визуальный опыт с лицами, ни входные данные с фовеа. Вместо этого наши результаты предполагают роль связи на больших расстояниях в определении местоположения селективности лица в человеческом мозге.
Исследования нейровизуализации за последние 20 лет предоставили подробную картину функциональной организации коры головного мозга человека. Десятки различных областей коры головного мозга находятся примерно в одном и том же месте практически у каждого типично развивающегося взрослого человека. Как эта сложная и систематическая организация строится на развитии и какова роль опыта? Здесь мы обращаемся к одному из аспектов этого давнего вопроса, проверяя, возникает ли веретенообразная область лица (FFA), ключевой корковый локус системы обработки человеческого лица, у людей, которые никогда не видели лиц.
Как здравый смысл, так и некоторые данные предполагают роль визуального опыта в развитии восприятия лица. Во-первых, лица составляют значительный процент всего визуального опыта в раннем младенчестве (1), и было бы удивительно, если бы этот богатый обучающий сигнал не использовался. Во-вторых, способности к восприятию лица и нейронные репрезентации лиц продолжают развиваться в течение многих лет после рождения (2–6). Хотя эти более поздние изменения могут в принципе отражать либо опыт, либо биологическое созревание, либо и то, и другое, некоторые данные указывают на то, что количество (7, 8) и вид (9, 10) опыта лица в детстве влияет на способности восприятия лица во взрослом возрасте.Однако во всех этих случаях неясно, играет ли визуальный опыт поучительную роль в подключении или уточнении схем для восприятия лица или разрешающую роль в поддержании этих схем (11).
Действительно, несколько линий доказательств предполагают, что некоторые аспекты восприятия лица могут развиваться при небольшом зрительном восприятии или вообще без него. В течение нескольких минут или, возможно, даже до рождения (12) младенцы отслеживают схематические лица больше, чем зашифрованные лица (13, 14). В течение нескольких дней после рождения младенцы могут поведенчески различать отдельные лица при изменении точки зрения и, в частности, на вертикальные, но не перевернутые лица (15–17).Данные ЭЭГ младенцев в возрасте от 1 до 4 дней показывают более сильную реакцию коры на вертикальное положение, чем на перевернутые схематические лица (18). Наконец, данные функциональной МРТ (фМРТ) показывают узнаваемую взрослую пространственную организацию реакций лица в коре головного мозга детенышей обезьян (19) и детей в возрасте 6 месяцев (20). Эти результаты показывают, что многие поведенческие и нейронные признаки системы обработки лиц взрослых можно наблюдать на очень раннем этапе развития, часто до обширного визуального опыта с лицами.
Чтобы более полно рассмотреть причинную роль визуального опыта в развитии механизмов обработки лиц, необходимо сравнение этих механизмов у людей с соответствующим визуальным опытом и без него.Два недавних исследования сделали именно это. Arcaro et al. (21) выращивали детенышей обезьян, не выставляя их лицом к лицу (при этом дополняя визуальный и социальный опыт другими стимулами), и обнаружили, что у этих обезьян, лишенных лица, не развивались области коры головного мозга, избирательные по лицу. Авторы пришли к выводу, что это открытие, по-видимому, является окончательным доказательством того, что видеть лица необходимо для формирования коры головного мозга, избирательной для лица. Однако другое недавнее исследование на людях (22) привело к противоположному выводу.Основываясь на обширной более ранней литературе, содержащей доказательства избирательных реакций по категориям для сцен (23), предметов и инструментов (24–32) в вентральном зрительном пути у врожденно слепых участников, в исследовании сообщалось о предпочтительных ответах для звуки, связанные с лицом, в веретенообразной извилине у врожденно слепых людей. Эти два исследования различаются модальностью стимула, видами и природой депривации, и, следовательно, их выводы не являются строго противоречивыми. Тем не менее, они предлагают разные выводы о роли визуального опыта с лицами в развитии коры головного мозга, избирательной к лицу, оставляя этот важный вопрос нерешенным.
Если действительно истинная избирательность лица может быть обнаружена у врожденно слепых участников в той же области боковой веретенообразной извилины, что и зрячие участники, это убедительно продемонстрировало бы, что визуальный опыт не является необходимым для возникновения избирательности лица в этом месте. Хотя van den Hurk et al. исследование (22) предоставляет доказательства этой гипотезы, оно не показало избирательности по лицу у отдельных слепых участников, что необходимо для точной характеристики места активации, и оно не предоставило независимую оценку профиля ответа этой области, поскольку необходимо для установления истинной селективности лица (т.е., существенно и значительно более высокая реакция на лица, чем на каждое из других испытанных условий). Кроме того, слуховые стимулы, использованные van den Hurk et al. (22) не позволяют обнаружить какие-либо избирательные реакции, которые могут быть основаны на информации о форме амода (25, 33, 34), которые могут передаваться визуальными или тактильными, но не слуховыми стимулами. Здесь мы используем тактильные стимулы и методы индивидуального анализа, чтобы определить, может ли истинная селективность лица возникнуть у врожденно слепых людей, не имеющих визуального опыта работы с лицами.
Мы также обращаемся к связанному с этим вопросу: почему FFA так систематически развивается в своем характерном месте, на латеральной стороне срединно-верзничной борозды (35)? Согласно одной из гипотез (36, 37), эта область становится настроенной на лица, потому что она получает структурированный входной сигнал преимущественно от фовеальной ретинотопной коры, которая, в свою очередь, непропорционально получает входной сигнал лица (поскольку лица обычно имеют ямки). Другая (неисключительная) гипотеза гласит, что эта область коры может иметь предвзятые особенности, например, изогнутые стимулы, приводящие к тому, что стимулы лица преимущественно задействуют и экспериментально модифицируют ответы в этой области (38–45).Третий класс гипотез утверждает, что не восходящий ввод, а взаимодействие с регионами более высокого уровня, вовлеченными в социальное познание и вознаграждение, склоняют этот регион к тому, чтобы он стал избирательным по лицу (38, 39). Эта идея согласуется с мнением о том, что избирательные по категориям регионы вентрального зрительного пути — это не просто зрительные процессоры, извлекающие информацию о разных категориях одинаковыми способами, но что каждый из них оптимизирован для обеспечения различного вида представления, адаптированного к отличительному постперцептивному использованию этого информация (29, 46).Такое богатое взаимодействие с постперцептивной обработкой может позволить этим типично зрительным областям брать на себя функции более высокого уровня у слепых людей (47, 48). Эти три гипотезы делают разные прогнозы относительно избирательности лица в веретенообразной извилине у врожденно слепых людей, которые мы здесь проверяем.
Результаты
Селективность по лицам в зрячих элементах управления.
Чтобы проверить наши методы, мы сначала проверили селективность лиц у зрячих контрольных участников ( n = 15), отсканировав их с помощью фМРТ, когда они просматривали визуализированные видео с 3D-напечатанными стимулами лица, лабиринта, руки и стула, поскольку они тактильно исследовали одни и те же раздражители с закрытыми глазами (рис.1).
Рис. 1.
Тактильные стимулы и дизайн эксперимента. ( A , Upper ) Изображения, показывающие визуализированный пример стимула из каждой из четырех категорий стимулов, используемых в Exp. 1: лица (F), руки (H), лабиринты (M) и стулья (C). ( Нижний ) План эксперимента, в котором участники тактильно исследовали стимулы, представленные в блоках. Зрячие участники наблюдали за этими визуализированными стимулами, вращающимися по глубине; как зрячие, так и слепые субъекты тактильно исследовали напечатанные на 3D-принтере версии этих стимулов.Как тактильные, так и визуальные эксперименты включали по два блока на каждую категорию стимула за прогон с 30-секундными блоками отдыха в начале, середине и конце каждого прогона. Во время среднего периода отдыха в тактильных условиях поворотный стол заменяли, чтобы представить новые стимулы во второй половине пробега. ( B ) Стимулы предъявлялись на вращающемся подносе, чтобы минимизировать движение кисти / руки. Испытуемые исследовали каждый 3D-печатный стимул в течение 6 секунд, после чего вращали поворотный стол, чтобы предъявить следующий стимул.( C ) На изображении показан пример участника внутри сканера, протягивающего руку, чтобы исследовать стимулы, напечатанные на 3D-принтере, на поворотном столе.
Контраст реакции всего мозга во время просмотра лиц по сравнению с просмотром рук, стульев и лабиринтов показал ожидаемую селективную активацию лица в каноническом месте латеральнее срединной борозды (35) у обоих отдельных участников (рис. 2 A ) и на карте перекрытия групповой активации (рис. 2 B ). Следуя установленным в нашей лаборатории методам (3, 49, 50), мы определили верхние селективные воксели лица для каждого участника в пределах ранее сообщенного анатомического ограничивающего участка (49) для FFA, количественно оценили ответ фМРТ в этих вокселях в продвинутом режиме. данные и статистически проверенная избирательность этих величин ответов среди участников (рис.2 С ). Этот метод позволяет избежать субъективности при выборе функциональной области интереса (FROI), успешно обнаруживает FROI, отобранную по лицу, у наиболее зрячих субъектов и позволяет избежать двойных или ложноположительных результатов, требуя перекрестной проверки (см. Приложение SI ). , Рис. S3 для контрольных анализов). Как и ожидалось для зрячих участников в условиях зрения, реакция на лица была значительно выше, чем у каждой из трех других категорий стимулов в имеющихся данных (рис.2 C и D ) (все P <0,005, парный тест t ).
Рис. 2.
Лицо-избирательность у зрячих и слепых. ( A ) Визуальные селективные активации по лицу (лица> руки, стулья и лабиринты) на исходной реконструированной поверхности для двух зрячих субъектов. ( B ) Процент зрячих субъектов, демонстрирующих значительную визуальную избирательность лица (при P <0,001 нескорректированного уровня у каждого участника) в каждом вокселе, зарегистрированном на fsaverage поверхности.Белая линия показывает расположение срединной борозды (mfs). ( C ) Среднее значение и SEM жирного ответа фМРТ для зрячих субъектов в 50 верхних селективных вокселях лица (идентифицированных с использованием независимых данных) во время визуального осмотра изображений лица, лабиринта, рук и стула. Данные отдельных субъектов накладываются соединенными линиями. ( D ) Профиль реакции визуально выбранной области лица (в удерживаемых данных) у зрячих участников как функция размера FROI (полосы ошибок указывают на SEM).Звездочки (*) указывают на значительную ( P <0,05) разницу между лицами и каждой из трех других категорий стимулов между испытуемыми. ( E — H ) То же, что и A – D , но для зрячих субъектов во время тактильного исследования стимулов, напечатанных на 3D-принтере. ( I — L ) То же, что и A – D , но для слепых во время тактильного исследования стимулов, напечатанных на 3D-принтере. * P <0,05, ** P <0,005, *** P <0.0005 и **** P <0,00005.
В тактильном состоянии контрасты всего мозга выявили селективную активацию лица в месте, аналогичном зрительной селективности лица у отдельных зрячих участников (рис. 2 E ) и на карте группового перекрытия (рис. 2 F ). ). Анализ FROI с использованием тактильных данных как для выбора, так и для количественной оценки удерживаемых ответов выявил значительно более высокую реакцию на лица, чем каждое из трех других условий (все P <0,05, парный тест t ).Кроме того, когда визуальные данные от одного и того же субъекта использовались для определения FROI, отобранных по лицу, мы наблюдали аналогичную тактильную избирательность по лицу (все P <0,05, парный тест t ). Обратите внимание, что абсолютная величина сигнала фМРТ была ниже для тактильного состояния у зрячих участников по сравнению с визуальным состоянием, но селективность ответа была аналогичной в двух модальностях [ t (28) = 0,13, P = 0,89, непарный t Тест , по индексу селективности] (см. Методы ).Наблюдение за тактильной избирательностью лица у зрячих участников демонстрирует эффективность наших стимулов и методов и, по-видимому, отражает визуальные образы тактильных стимулов (51, 52). Но зрячие тактильные отклики не решают главного вопроса этой статьи — может ли избирательность лица у веретенообразной формы возникнуть без визуального восприятия лиц. Чтобы ответить на этот вопрос, мы обратимся к врожденно слепым участникам.
Избирательность по лицам у слепых участников.
Чтобы проверить, проявляют ли слепые участники избирательность в отношении лиц, несмотря на отсутствие у них визуального опыта, мы сканировали врожденно слепых участников по той же парадигме, что и зрячие, поскольку они тактильно исследовали 3D-отпечатанные лица, лабиринт, руки и стимулы стула.Действительно, контрастные карты всего мозга выявляют селективные по лицу активации на карте перекрытия групповой активации (рис. 2 J ) и у большинства слепых субъектов, анализируемых индивидуально (рис. 2 I и SI, приложение , рис. S1). . Эти активации были обнаружены в каноническом месте (Рис. 2 I и J ), латеральнее срединной борозды (35). Следуя методу, используемому для зрячих участников, мы определили верхние тактильные селективные воксели лица для каждого субъекта в ранее опубликованных пакетах анатомических ограничений для визуального FFA ( SI Приложение , рис.S2) и измерили ответ фМРТ в этих вокселях в полученных данных. Реакция на тактильные лица была значительно выше, чем на каждый из трех других классов стимулов (все P <0,005, парный тест t ). Хотя абсолютная величина сигнала фМРТ была ниже для слепых участников, тактильно исследующих стимулы, чем для зрячих участников, просматривающих стимулы, избирательность ответа была одинаковой в двух группах [ t (28) = 0,05, P = 0.96, непарный тест t , по индексу селективности между слепыми и зрячими тактильными ощущениями и t (28) = 0,12, P = 0,90, по индексу селективности между слепыми и зрячими тактильными ощущениями]. Обратите внимание, что FROI были определены для каждого участника как 50 наиболее значимых вокселей в пределах участка анатомических ограничений, даже если воксели фактически не достигли значимости у этого участника, что обеспечивает беспристрастную оценку средней избирательности по лицу для всей группы. Эти анализы выявляют явную избирательность по лицу у большинства врожденно слепых участников в том же месте, что и у зрячих.Таким образом, видение лиц не является необходимым для развития избирательности лиц в боковой веретенообразной извилине.
Три дополнительных анализа подтверждают сходство в анатомическом расположении избирательных ответов по лицам для слепых участников, ощущающих лица, и для зрячих участников, просматривающих лица. Во-первых, групповой анализ всего мозга не обнаружил вокселей, показывающих взаимодействие испытуемой группы (зрячий зрительный или тактильный слепой) с помощью стимулов, связанных с лицом / лицом, даже при очень либеральном пороге P <0.05 без коррекции, за исключением области в боковой борозде, которая показала большую избирательность сцены у зрячих, чем у слепых участников. Во-вторых, новый анализ на основе FROI с использованием нарисованной вручную анатомической ограничивающей области для FFA на основе точных анатомических ориентиров от Weiner et al. (35) продемонстрировали аналогичную избирательность по лицу при тактильных слепых данных ( SI Приложение , рис. S2). Наконец, нет доказательств дифференциальной латерализации селективности лица у слепых и зрячих (см. Приложение SI, приложение , рис.S4 для соответствующей статистики). Взятые вместе, эти анализы предполагают, что тактильная селективность лица у слепых возникает в анатомическом месте, аналогичном зрительной селективности лица у зрячих.
Почему активация выбора лица возникает там, где она есть?
Наше открытие тактильной селективной активации лица в веретенообразной извилине слепых субъектов поднимает другой фундаментальный вопрос: почему селективность лица возникает так систематически в этом конкретном участке коры, латеральнее срединно-порочной борозды (39)? Согласно одной широко распространенной гипотезе, этот корковый локус становится избирательным по лицу, потому что он получает структурированную визуальную информацию, направляемую через определенные связи из фовеальной (в отличие от периферической) ретинотопной коры, где чаще всего возникают лицевые стимулы (40–43).Эта гипотеза не может объяснить анатомическое расположение лица в группе слепых, наблюдаемой здесь, потому что эти субъекты вообще никогда не получали какой-либо структурированной визуальной информации.
Согласно другой широко обсуждаемой гипотезе, эта область смещена для искривленных стимулов, как часть ранней развивающейся прото-карты, основанной на форме, на которой впоследствии строится высокоуровневая селективность лица (53). Если эта прото-карта является строго визуальной, то она не может учитывать местоположение избирательности лица, которую мы наблюдаем у слепых участников.Однако, если он амодальный, реагируя также на тактильную форму (33, 54), он мог бы. В этом случае области тактильного выбора лица у слепых участников должны реагировать преимущественно на изогнутые, а не на прямолинейные формы. Мы проверили эту гипотезу во втором эксперименте, в котором семь из наших исходных врожденно слепых участников вернулись для нового сеанса сканирования, в котором они тактильно исследовали набор стимулов, состоящий из четырех категорий стимулов, используемых ранее, и двух дополнительных категорий: сфероидов и кубоидов.Этот экспериментальный план позволил нам воспроизвести селективность лица в дополнительном экспериментальном сеансе и определить, были ли воксели, избирательные по лицу, предпочтительнее для криволинейных форм (сфероидов) по сравнению с прямолинейными формами (кубоиды). Активации, селективные по лицу, были воспроизведены во втором сеансе эксперимента (фиг. 3 A , вверху справа ). В строгом тесте репликации мы количественно оценили избирательность по лицу, выбрав верхние селективные по лицу воксели из первого сеанса эксперимента в пределах участка FFA, пространственно зарегистрировали эти данные с данными из второго сеанса у того же участника и измерили ответ. этого же FROI во второй экспериментальной сессии.Мы воспроизвели селективность лица из нашего первого эксперимента (рис. 3 B ). Кроме того, мы обнаружили, что селективные по граням воксели не реагировали сильнее на сфероиды, чем кубоиды [ t (6) = -0,65, P = 0,54, парный тест t ]. Эти данные свидетельствуют против смещения кривизны в ранее существовавшей карте амодальной формы как детерминанты кортикального локуса избирательности лица у слепых субъектов.
Рис. 3.
Ответы избирательных участков лица у слепых участников во время тактильного исследования искривленных стимулов и слухового прослушивания звуковых категорий.( A ) Активация по выбору лица (лица> руки, стулья и сцены) в примере слепого субъекта во время тактильного исследования 3D-напечатанных стимулов в сеансе 1 ( слева, ), воспроизведенная в дополнительном последующем сканировании с дополнительные изогнутые стимулы ( Right Upper ) и в слуховой парадигме ( Lower Right ). ( Справа ) Среднее значение и SEM для участников ответа ФМРТ ЖИРНЫМ шрифтом в 50 верхних селективных вокселях по лицу (идентифицированных из сеанса 1) во время сеанса.( B ) Тактильное исследование сфероидов и кубоидов (в дополнение к стимулам лица, лабиринта, руки, стула, как и раньше) и ( C ) слуховое представление звуков, связанных с лицом, сценой, телом и объектами. В B и C индивидуальные данные наложены на соединенные линии; * P <0,05, ** P <0,005 (двусторонний тест t ). н.с. не имеет значения.
Если ни ранние ретинотопные, ни основанные на особенностях прото-карты (40, 55) не определяют кортикальный локус селективности лица у слепых участников, что делает? У зрячих субъектов категории селективных областей в вентральном зрительном пути служат не только для анализа визуальной информации, но и для извлечения самых разных представлений, которые служат входными данными для областей более высокого уровня, вовлеченных в социальное познание, действия с визуальным управлением и навигацию (29 , 38, 39, 47).Возможно, именно их взаимодействие с этими высокоуровневыми кортикальными областями стимулирует развитие селективности лица в этом месте (38, 39). Ранее упомянутая предпочтительная реакция на звуки, связанные с лицом, у веретенообразных слепых субъектов (22) дает некоторые доказательства этой гипотезы. Чтобы проверить надежность этого результата и спросить, возникает ли избирательность лица у слепых участников в одном и том же месте для слуховых и тактильных стимулов, мы затем выполнили точную репликацию Van den Hurk et al.(22) исследование семи слепых от рождения участников нашего пула.
Участники слышали те же короткие отрывки звуков, связанных с лицом, телом, объектами и сценой, которые использовались в предыдущем исследовании (22), при сканировании с помощью фМРТ. Примеры звуков, связанных с лицом, включали аудиоклипы, в которых люди смеются или жуют, звуки, связанные с телом, включали хлопки или ходьбу, звуки, связанные с объектами, включали прыжок мяча и запуск автомобиля, а звуки, связанные со сценой, включали клипы с разбивающимися волнами и толпой ресторан.Действительно, мы обнаружили надежно избирательные реакции на звуки лица по сравнению со звуками, связанными с объектами, сценой и телом, у отдельных слепых участников, повторяя van den Hurk et al. (22). Слуховые активации лица были обнаружены примерно в тех же местах, что и тактильные активации лица (Рис.3 A и SI Приложение , Рис. S1), хотя воксельная связь между двумя паттернами активации внутри пакета FFA у каждого участника была слабая (среднее для субъектов корреляции Пирсона между наблюдаемыми значениями t на участке лица между тактильным и слуховым экспериментом, R = 0.14; корреляция между тактильными Exp. 1 и тактильный Exp. 2, R = 0,23). Чтобы количественно оценить слуховую избирательность лица, мы выбрали воксели, избирательные по лицу, в посылках FFA из тактильной парадигмы и протестировали их на слуховой парадигме. Этот анализ выявил четкую избирательность в отношении звуков лица в группе (рис. 3 C ) в области, показывающей тактильную избирательность лица у слепых участников.
Предсказывают ли подобные отпечатки пальцев локус селективности лиц у зрячих и слепых?
Остается вопрос: что такого особенного в боковой веретенообразной извилине, которая отмечает эту область как локус, в котором будет развиваться селективность лица? Давняя гипотеза утверждает, что связь мозга на большие расстояния, большая часть которой присутствует при рождении, ограничивает функциональное развитие коры (39, 46, 56–62).Доказательства этой гипотезы «ограничения связности» получены из демонстрации отличительных «отпечатков пальцев связи» многих областей коры у взрослых (57, 63, 64), включая FFA (57, 64). Чтобы проверить эту гипотезу в нашей группе зрячих и слепых участников, мы использовали корреляции фМРТ в состоянии покоя в качестве прокси для подключения на большие расстояния (65). Сначала мы спросили, сходен ли «отпечаток корреляции» (CF) избирательных участков лица у слепых и зрячих. Отпечаток пальца каждой вершины веретенообразной формы был определен как корреляция между ходом времени в состоянии покоя этой вершины и средним ходом времени в каждой из 355 областей коры при стандартной парцелляции всего мозга (66).Отпечатки пальцев, соответствующие вершинам выборки лица, сильно коррелировали между зрячими и слепыми в обоих полушариях. В частности, 355-мерный вектор корреляций между избирательными по лицу вокселами (усредненный по 200 наиболее избирательным по лицу вокселям в каждом полушарии и индивидуума, а затем усредненный по участникам) и каждым из 355 анатомических участков сильно коррелировал между слепыми. и зрячие участники (среднее значение ± стандартное отклонение для 1000 оценок начальной загрузки для разных субъектов, левое полушарие Pearson R = 0.82 ± 0,08, правое полушарие Pearson R = 0,76 ± 0,09). Напротив, аналогичные корреляции между вершинами, отобранными для наилучшей селективной выборки лиц и сцен, бутстрап подвергся повторной выборке 1000 раз по предметам, левое полушарие Пирсона R = 0,55 ± 0,12, правое полушарие Пирсон R = 0,60 ± 0,09, P = 0, тест перестановки между выборочными по лицам и сценам на преобразованных Фишером корреляциях.
Затем мы проверили более сильную версию гипотезы связности, построив вычислительные модели, которые изучают отображение CF каждой вершины на функциональные активации.В частности, следуя установленным методам (64, 65), мы обучили модели изучению воксельной связи между CF и избирательностью по лицу, и протестировали их с помощью перекрестной проверки «оставить один-субъект-исключить». Сначала мы проверили эффективность этого подхода отдельно для зрячих и слепых групп. Модели, обученные на данных внутри каждой группы (слепой или зрячей), в среднем предсказывали пространственный паттерн избирательной активации лица каждого удерживаемого субъекта значительно лучше, чем групповой анализ функциональной избирательности других участников в этой группе (рис.4 B ) ( P <0,05, парный тест t с прогнозами из группового анализа случайных эффектов). Наблюдаемые предсказания были значительно выше в группе зрячих участников, чем в группе слепых участников [непарный тест t между преобразованными Фишером корреляциями между зрячими предсказаниями, основанными на зрячих данных, и слепыми предсказаниями, основанными на слепых данных, t (24) = 2,13 , P = 0,043], что согласуется с наблюдением, что избирательность по лицу более изменчива у слепых участников (см. Обсуждение ), чем у зрячих участников.Как и ожидалось, предсказания модели также коррелировали с наблюдаемой изменчивостью в веретенообразной целевой области (корреляция Пирсона между дисперсией t -значений в веретенообразной форме и наблюдаемым предсказанием, R = 0,47, P = 0,016). Этот результат показывает, что действительно возможно научиться надежному отображению от воксельных CF к воксельным функциям селективной функциональной активации в каждой группе.
Рис. 4.
CF предсказывают пространственное положение селективности лица.( A , Top ) Наблюдаемая избирательная активация по лицу у примерного слепого субъекта ( z -балльные единицы). Предсказанные активации для одного и того же субъекта на основе CF этого человека с использованием модели, обученной на тактильных активациях других слепых субъектов ( слева, ) или на визуальных активациях зрячих субъектов ( справа, ). ( Bottom ) предсказал активацию на основе группового анализа реакций выбора лица у других слепых субъектов. ( B ) Прогнозирование модели для слепых и зрячих субъектов.Каждая точка представляет собой точность прогнозирования модели для одностороннего ( слева, , красный) и слепого ( справа, , зеленый) объекта. Прогнозы модели были получены из CF, полученных из одной и той же группы (левый столбец в каждом наборе), анализа функциональной группы оставшихся субъектов (средний столбец в каждом наборе) или из CF противоположной группы (правый столбец в каждом наборе). Парные тесты t были выполнены на данных, преобразованных Фишером. * P <0,05, ** P <0.005, *** P <0,0005, **** P <0,00005 и n.s., не имеет значения. ( C ) Точность прогнозирования модели избирательности лица для зрячих (зрительные ответы) и слепых (тактильные ответы) на основе CF, включая только целевые области в пределах одной доли за раз. Статистика показывает значительно лучший прогноз на основе CF, чем на основе анализа случайных эффектов избирательности лица в остальных случаях.
Затем мы спросили, обучалась ли модель на одной группе субъектов (например,g., зрячие участники) будут обобщены на другую группу субъектов (например, слепых участников) в качестве более сильного теста на сходство в связности избирательных участков лица между зрячими и слепыми участниками. Действительно, эти предсказания пространственного паттерна избирательности лица были обнаружены не только для удерживаемых субъектов в каждой группе, но также и для субъектов в другой группе, значительно превосходя прогнозы функциональной активации других участников в той же группе. (Рисунок.4 A и B ) ( P <0,05, парный тест t с прогнозами из группового анализа случайных эффектов). Обратите внимание, однако, что избирательная активация по лицу у зрячих участников была лучше предсказана CF от зрячих участников, чем слепых участников [парный тест t t (12) = 2,32, P = 0,039]. Хотя корреляции фМРТ в покое являются несовершенным показателем структурной связности (67), эти результаты предполагают, что избирательность лица у веретенообразных отчасти предсказывается аналогичной связностью на больших расстояниях у зрячих и слепых участников.
Предыдущий анализ не говорит нам, какие связи наиболее предсказывают функциональную активацию у зрячих и слепых участников. Чтобы ответить на этот вопрос, мы повторно проанализировали CF, используя только целевые области из одной доли (лобной, височной, затылочной и височной) за раз. Здесь мы обнаруживаем, что, хотя визуальная избирательность лица по вокселям у зрячих субъектов в значительной степени предсказывалась по CF для каждой из четырех долей мозга индивидуально ( P <0.05) (рис. 4 C ), у слепых субъектов тактильная селективность лица достоверно предсказывалась только для теменных и лобных областей. Эти данные указывают на то, что нисходящий вклад в развитие селективности лица веретенообразной формы у слепых субъектов.
Обсуждение
Как функционально специфические области коры связаны в развитии и какова роль опыта? Это исследование проверяет три широко обсуждаемых класса (неисключительных) гипотез о происхождении FFA и представляет доказательства против двух из них.Наше открытие устойчивых реакций избирательного выбора лица в боковой веретенообразной извилине у большинства слепых от рождения участников указывает на то, что ни предпочтительный фовеальный вход, ни перцептивный опыт, ни вообще какой-либо визуальный опыт не нужны для развития ответов избирательного лица в этой области. Наше дальнейшее открытие, что одна и та же область не реагирует больше на изогнутые формы, чем на прямолинейные формы у слепых участников, ставит под сомнение гипотезу о том, что избирательность лица возникает там, где она возникает в коре головного мозга, потому что эта область составляет смещенную кривизной часть раннего развивающегося прототипа. -карта.С другой стороны, наше открытие очень похожих CF, предсказывающих избирательность лица для зрячих и слепых участников, особенно из теменных и лобных областей, подтверждает гипотезу о том, что нисходящие связи играют роль в определении локуса, в котором развивается избирательность по лицу.
Наши результаты расширяют предыдущую работу по двум важным направлениям. Во-первых, хотя в предыдущих исследованиях сообщалось о некоторых доказательствах корковой избирательности у врожденно слепых участников для категорий стимулов, таких как сцены и большие объекты (23, 24), инструменты (68) и тела (69, 70), предыдущие работы либо не увенчались успехом. чтобы обнаружить избирательность лица в веретенообразной форме у слепых участников (27, 71, 72) или сообщили только о предпочтительных ответах в групповом анализе (22, 30).Наши анализы соответствуют более высокой планке для демонстрации избирательности лица, показывая: 1) устойчивую избирательность лица у отдельных слепых субъектов, 2) значительно более сильные реакции этих областей на каждое из трех других условий стимула, 3) аналогичный индекс избирательности этой области. для слепых и зрячих участников, 4) внутренняя репликация избирательности лица в веретенообразной форме через сеансы визуализации и через сенсорные модальности, и 5) демонстрация того, что тактильная избирательность лица у слепых не может быть объяснена избирательностью по тактильной кривизне.Во-вторых, наши результаты предоставляют доказательства против наиболее распространенных теорий, объясняющих, почему избирательность лица развивается в его конкретном стереотипном кортикальном положении. По-видимому, ни опыт фовеального лица, ни предвзятость по искривлению не требуются. Вместо этого мы представляем доказательства того, что структура структурных связей с другими кортикальными областями может играть ключевую роль в определении места возникновения избирательности лица. В частности, мы продемонстрировали, что CF, предсказывающий визуальную селективность лица для зрячих субъектов, может также предсказывать паттерн тактильной селективности лица у слепых (и наоборот).Используя этот подход прогнозного моделирования, мы также находим предварительные доказательства доминирующей роли нисходящих связей лобной и теменной коры в определении локуса селективности лица у слепых субъектов (38).
Обычным ограничением исследований со слепыми участниками является отсутствие документации о полном отсутствии способностей к восприятию зрительных образов в первые недели жизни. Слепых новорожденных редко проверяют с помощью тщательных психофизических методов, и лишь немногие из них до сих пор имеют медицинские записи с первых недель жизни.Наиболее убедительные доказательства получены от редких участников с врожденной двусторонней анофтальмией, но только в одно исследование было включено достаточное количество этих участников, чтобы проанализировать их данные отдельно (22). Здесь мы следовали практике большинства других исследований с участием врожденно слепых людей, собирая все доказательства, которые наши участники могли предоставить о точном характере их слепоты ( SI Приложение , Таблица S1), и включая участников нашего исследования, если они сообщили диагноз слепоты при рождении и отсутствие свидетельств или воспоминаний о том, что когда-либо видели зрительные образы.Хотя мы не можем окончательно исключить некоторые очень рудиментарные ранние паттерны видения в этой группе, наша подгруппа, сообщающая об отсутствии светового восприятия с рождения, вряд ли когда-либо видела какие-либо зрительные паттерны. В эту группу вошли только пять человек, чего было недостаточно для того, чтобы их тактильная селективность лица достигла значимости при отдельном анализе, но данные из этой группы очень похожи на данные остальных наших участников ( SI Приложение , рис. S6) .
Остается еще много важных вопросов.Во-первых, является ли избирательность лица врожденной, в том смысле, что она не требует никакого опыта восприятия лиц? Настоящее исследование не дает ответа на этот вопрос, потому что, хотя наши слепые от рождения участники никогда не видели лиц, они определенно чувствовали их и слышали звуки, которые они производят. Например, слепые люди обычно не касаются лиц во время социальных взаимодействий, но обязательно чувствуют собственное лицо, а иногда и лица близких. Остается неизвестным, является ли этот тактильный опыт с лицами необходимым для формирования избирательности лица у веретенообразных.
Во-вторых, что на самом деле вычисляется в избирательной коре головного мозга у веретенообразных слепых участников? Кажется маловероятным, что основная функция этой области у слепых людей — тактильное различение отдельных лиц, задача, которую они выполняют редко. Одна из возможностей состоит в том, что «естественной» функцией FFA является индивидуальное распознавание, которое в первую очередь является визуальным у зрячих людей (например, распознавание лиц), но может брать на себя аналогичные функции в других модальностях в случае слепоты (25, 33, 58, 62, 73), например обработка голосовой идентификации (74, 75).Эта гипотеза получила смешанную поддержку в прошлом (76, 77), но потенциально может объяснить наблюдаемые более высокие реакции на тактильные лица и слуховые звуки лица, обнаруженные здесь. Другая возможность состоит в том, что у слепых эта область берет на себя более высокоуровневую социальную функцию, такую как определение психических состояний у других [но см. Бедни и др. (78)]. Интересным параллельным случаем является открытие, что «визуальная область словоформы» у слепых на самом деле обрабатывает не орфографическую, а лингвистическую информацию высокого уровня (47).Точно так же, если «слепая FFA» фактически вычисляет социальную информацию более высокого уровня, это может объяснить еще одну загадку в наших данных, а именно, что не все слепые участники демонстрируют избирательную реакцию по лицу на тактильные и слуховые стимулы. Эта вариабельность наших данных не объясняется вариабельностью по возрасту (корреляция возраста с индексом избирательности = 0,03, P = 0,89), полу ( R = -0,12, P = 0,65) или выполнением задания ( R = 0,06, P = 0.81). Возможно, функция более высокого уровня, реализованная в этой области у слепых участников, не является такой автоматической, как визуальное распознавание лиц у зрячих участников.
Наконец, хотя наши результаты четко согласуются с результатами van den Hurk et al. (22), кажется, что их труднее согласовать с предыдущим выводом о том, что обезьяны, выращенные без лицевого опыта, не проявляют избирательных реакций по лицу (21). Важно отметить, однако, что слуховые и тактильные реакции на лица, насколько нам известно, не были проверены на обезьянах, лишенных лица, и, возможно, они покажут то же самое, что мы видим у людей.Если это так, было бы информативно проверить, необходим ли слуховой или тактильный опыт общения с лицами во время развития для возникновения избирательных реакций у обезьян, лишенных визуального опыта общения с лицами (что мы не можем проверить на людях). Перед этими данными следует отметить ключевое различие между данными по обезьянам с лишенным лица и слепым людям состоит в том, что обезьяны, которым были представлены визуальные лица, не показывали никаких признаков их распознавания, без предпочтения в поисках лиц и лицРуки. В отличие от этого, все слепые участники нашего исследования сразу распознали стимулы, отпечатанные на 3D-принтере, как лица, не сказав им ничего. Обнаружение присутствия собратьев-приматов может иметь решающее значение для получения реакции выбора лица.
Таким образом, мы показываем, что визуальный опыт не является необходимым для развития избирательности лица в боковой веретенообразной извилине, и, по-видимому, не является основанной на особенностях прото-картой в этой области коры. Вместо этого наши данные предполагают, что связь этой области на большие расстояния, которая развивается независимо от зрительного восприятия, может отмечать боковую веретенообразную извилину как место коры, избирательной для лица.
Методы
Участники.
Пятнадцать зрячих и 15 слепых испытуемых участвовали в эксперименте (6 женщин в группе зрячих и 7 женщин в группе слепых, средний возраст ± SEM 29 ± 2 года для зрячих; 28 ± 2 года для слепых участников). Два дополнительных слепых субъекта, которые были набраны, были исключены, потому что им было неудобно работать со сканером. Семь субъектов из группы слепых участвовали в Exps. 2 и 3 в дополнительном сеансе эксперимента (четыре женщины, среднее значение ± стандартная ошибка среднего, возраст 28 ± 3 года).Все исследования были одобрены Комитетом по использованию людей в качестве объектов эксперимента Массачусетского технологического института (MIT). Участники предоставили информированное письменное согласие перед экспериментом и получили компенсацию за свое время. Все слепые участники, отобранные для исследования, были либо полностью слепыми, либо с рождения имели только световое восприятие. Ни один из наших испытуемых не сообщил о каких-либо воспоминаниях о пространственном или предметном видении. Подробная информация о слепых пациентах представлена в Приложении SI , Таблица S1.
Стимулы.
Эксперимент 1.
In Exp. 1, слепые испытуемые тактильно исследовали стимулы, напечатанные на 3D-принтере, а зрячие испытуемые исследовали те же стимулы визуально и тактильно. Тактильные стимулы состояли из пяти экземпляров каждой из четырех категорий стимулов: лица, лабиринты, стулья и руки. 3D-модели стимулов лица были созданы с помощью 3D-печати FaceGen (программное обеспечение было приобретено и загружено с https://facegen.com/3dprint.htm). Стимулы лица печатались на базе размером 4 × 4 см и имели высоту 7 см.Трехмерные модели лабиринтов были похожи на макеты домов и были разработаны в Autodesk 3ds Max (Academic License, v2017). Планы лабиринта размером 5 × 5 см состояли из прямых стен с входами и выходами и небольшой приподнятой платформы. 3D-модели для стимулов рук были приобретены у Dosch Design (Dosch 3D: набор данных рук, с сайта doschdesign.com). После этого загруженные трехмерные стимулы были адаптированы для удаления предплечья и включения только запястья и кисти. Стимулы фиксировались на базе 4 × 4 см, имели высоту ~ 7 см и включали пять типовых конфигураций рук.Наконец, 3D-модели стульев были загружены из общедоступных баз данных (с archive3d.net). Все стимулы представляли собой кресла разного типа, каждый был напечатан на основе 5 × 5 см и имел высоту ~ 7 см. Поскольку субъекты выполняли одноразовую идентификационную задачу внутри сканера, мы напечатали на 3D-принтере две идентичные копии каждого стимула, создав общий набор из 40 3D-печатных моделей (4 категории объектов × 5 экземпляров на категорию × 2 копии). 3D-модели были напечатаны на стереолитографическом 3D-принтере FormLabs (SLA) (Form-2) с использованием серой фотополимерной смолы (FLGPGR04).Это гарантировало, что свойства текстуры поверхности не могли различить образцы или категории стимулов. 3D-отпечатки, созданные на 3D-принтерах в стиле SLA, имеют небольшие деформации в местах соединения опорных лесов с моделью. Мы убедились, что эти деформации не могут быть диагностированы, используя одинаковые модели каркасов (для стимулов лица и рук) или записывая их в архив после обработки и лечения моделей (стимулы от кресла). Лабиринты можно было напечатать без поддерживающих каркасов, из-за чего на этих стимулах не было деформаций, связанных с 3D-печатью.Тем не менее, мы проинструктировали испытуемых игнорировать небольшие деформации при оценке условий односторонности. Визуальные стимулы для зрячих субъектов включали короткие 6-секундные видеоанимации трехмерных изображений одних и тех же трехмерных стимулов (серым на черном фоне), вращающихся по глубине. Анимации были визуализированы непосредственно из Autodesk 3Ds Max. Каждый стимул располагался под углом зрения около 8 ° вокруг расположенной в центре черной фиксирующей точки. Файлы .STL, используемые для 3D-печати различных стимулов, и видеофайлы анимации можно загрузить с GitHub по адресу https: // github.com / ratanmurty / pnas2020.
Эксперимент 2.
Стимулы для опыта. 2 включены стимулы от Exp. 1 (лицо, лабиринт, рука и стул) и две дополнительные категории объектов: сфероиды и кубоиды. 3D-модели были созданы с нуля в Autodesk 3Ds Max. Сфероиды имели форму яйца, а кубы имели форму коробки, и каждый был напечатан на основе 4 × 4 см. Мы напечатали на 3D-принтере по две копии каждого из четырех экземпляров сфероидов и кубоидов (три варианта в плоскостях x , y и z плюс одна сфера / куб), которые различались по удлинению.Каждый стимул был высотой ~ 7 см.
Эксперимент 3.
Слуховые стимулы, используемые в Exp. 3 были загружены с https://osf.io/s2pa9/, любезно предоставлены авторами предыдущего исследования (22). Каждый слуховой стимул представлял собой короткий аудиоклип длительностью ~ 1800 мс, а набор стимулов состоял из 64 уникальных аудиоклипов, по 16 в каждой из четырех слуховых категорий (лицо, тело, объект и сцена). Примеры стимулов, связанных с лицом, включали записанные звуки смеха и жевания людей, стимулы, связанные с телом, включали аудиоклипы, в которых люди хлопали в ладоши и ходили, звуки, связанные с объектами, включали звуки прыгающего мяча и запуска автомобиля, а также звуки, связанные со сценой. клипы с грохотом волн и переполненный ресторан.Общая интенсивность звука согласовывалась между стимулами путем нормализации среднеквадратичного значения уровней звукового давления. Мы не проводили никакой дополнительной нормализации стимулов, за исключением того, чтобы убедиться, что уровни интенсивности звука находятся в комфортном слуховом диапазоне для наших испытуемых.
Парадигма.
Все 15 слепых и 15 зрячих участвовали в Exp. 1. Слепые и зрячие испытуемые исследовали лица, лабиринты, руки и стулья, напечатанные на 3D-принтере, представленные на МРТ-совместимом поворотном столе внутри фМРТ-сканера, при выполнении ортогональной задачи идентификации с одной спиной (средняя точность испытуемого в задаче с одной спиной: 79 %, 81%, 89% и 86% для стимулов лица, лабиринта, рук и стула соответственно).Двусторонний дисперсионный анализ с группой субъектов (слепой и зрячий) и типами стимулов (лицо, лабиринт, рука и стул) в качестве факторов выявил значительный эффект категории стимула [ F (3, 112) = 18,28, P <0,00005], но никакого эффекта от предметной группы, и без взаимодействия между предметной группой и категорией стимула. Каждый прогон включал три 30-секундных периода отдыха в начале, середине и конце прогона и восемь блоков тактильных стимулов продолжительностью 24 секунды (по два блока на категорию стимулов) (рис. 1).Во время каждого тактильного стимульного блока слепые испытуемые тактильно исследовали четыре 3D-отпечатанных стимула (три уникальных стимула плюс один обратный стимул) по очереди в течение 6 с каждый, с синхронизацией по вращению поворотных столов, к которым стимулы были прикреплены на липучках (рис. ). После того, как каждый стимул был исследован в четырех блоках (по одному на категорию стимулов), поворотный стол был заменен во время среднего периода отдыха с новым порядком стимулов (рис. 1). Тактильные сеансы чередовались с 3-4-минутным сканированием в состоянии покоя, во время которого испытуемым предлагалось оставаться как можно более неподвижным.Каждый поворотный стол включал 16 стимулов (4 категории стимулов × 4 образца на категорию), а порядки стимулов и категорий были рандомизированы в ходе экспериментальных прогонов (путем изменения положения стимулов на поворотном столе). Каждый запуск длился 4 мин 42 с, и 14 из 15 слепых испытуемых выполнили 10 запусков (1 участник выполнил 8 запусков) эксперимента. Слепые испытуемые не обучались стимулам или задаче, а были ознакомлены с процедурой менее чем за 5 минут до сканирования. Также были приняты меры к тому, чтобы перед сканированием участникам не была предоставлена информация ни о какой из категорий стимулов.Зрячие участники выполняли аналогичную задачу визуально (средняя точность в задаче с одной спиной: 99%, 97%, 99% и 99% для стимулов лица, лабиринта, руки и стула соответственно), просматривая изображения тех же трехмерных изображений. печатные стимулы, вращающиеся по глубине, представленные с одинаковой скоростью и в одном дизайне (четыре образца стимула на категорию стимула на блок). Зрячие испытуемые выполнили пять пробежек в течение экспериментальной сессии.
Подмножество слепых субъектов ( n = 7) вернулись на второй сеанс (от нескольких дней до нескольких месяцев после первого сеанса) и приняли участие в Exps.2 и 3. В Exp. 2, испытуемые выполнили 10 прогонов с использованием такой же парадигмы тактильных ощущений, что и в Exp. 1, но вертушки включали две дополнительные категории стимулов помимо лиц, лабиринтов, рук и стульев: сфероиды и кубоиды. В дополнительном сеансе пробегает Exp. 2 чередовались с пробегами из Exp. 3, который является прямым воспроизведением слуховой парадигмы из ранее опубликованного исследования (22). Презентация стимулов и дизайн задания были такими же, как в предыдущем исследовании (22). Вкратце, испытуемых попросили сравнить концептуальное несхожесть каждого слухового стимула с предыдущим слуховым стимулом по шкале от 1 до 4.Каждый слуховой стимул представлял собой короткий аудиоклип длительностью ~ 1800 мс, а набор стимулов состоял из 64 уникальных аудиоклипов, по 16 в каждой из 4 слуховых категорий (лицо, тело, объект и сцена). Стимулы были представлены в виде блоков, по четыре блока на категорию в каждом прогоне. Каждый блок состоял из восьми стимулов на категорию, выбранных случайным образом из 16 возможных наборов стимулов. Каждый запуск длился 7 минут 30 секунд, и каждый испытуемый участвовал в девяти запусках этой слуховой парадигмы, чередующихся с Exp. 2 тактильная парадигма.
Сбор данных.
Все эксперименты были выполнены в Центре визуализации Athinoula A. Martinos в Массачусетском технологическом институте на сканере Siemens 3-T MAGNETOM Prisma с 32-канальной головной катушкой. Мы получили T1-взвешенное (мультиэхо MPRAGE) анатомическое сканирование с высоким разрешением во время первого сеанса сканирования (параметры получения: 176 срезов, размер вокселя: 1 × 1 × 1 мм, время повторения [TR] = 2500 мс, время эхо [TE ] = 2,9 мс, угол поворота = 8 o ). Функциональное сканирование включало 141 и 225 T2 * -взвешенных эхопланарных изображений в зависимости от уровня кислорода в крови (жирный шрифт) для каждого тактильного и слухового прохода, соответственно (параметры получения: одновременное чередование мультиспиральных срезов 2, TR = 2000 мс, TE = 30 мс, воксель -размер изотропный 2 мм, количество срезов = 52, угол переворота: 90 °, эхо-интервал 0.54 мс, частичный сбор Фурье 7/8 фаз). Данные о состоянии покоя были получены для 13 из 15 слепых и 13 из 15 зрячих субъектов, участвовавших в Exp. 1 (параметры сканирования: TR = 1500 мс, TE = 32 мс, размер вокселя 2,5 × 2,5 × 2,5 мм, изотропный, угол поворота 70 °, продолжительность состояния покоя: 27,5 ± 0,5 мин для зрячих и 27,2 ± 0,5 мин. для слепых). Зрячие участники закрывали глаза во время пробежек в состоянии покоя.
Предварительная обработка данных и моделирование.
Предварительная обработка данных фМРТ и обобщенное линейное моделирование были выполнены на Freesurfer (v6.0,0; скачано с: https://surfer.nmr.mgh.harvard.edu/fswiki/). Предварительная обработка данных включала коррекцию времени среза, коррекцию движения каждого функционального цикла, согласование с анатомическими данными каждого субъекта и сглаживание с использованием 5-миллиметрового ядра Гаусса полной ширины и половины максимального значения. Обобщенное линейное моделирование включало один регрессор для каждого условия стимула, а также мешающие регрессоры для удаления линейного дрейфа и коррекции движения за цикл. Данные были проанализированы в собственном объеме каждого испытуемого (анализ на естественной поверхности испытуемых также привел к качественно схожим результатам).Карты активации были спроецированы на исходную реконструированную поверхность для облегчения визуализации. Для анализа на уровне группы данные были сопоставлены со стандартными анатомическими координатами поверхности с использованием шаблона Freesurfer fsaverage (MNI305). Поскольку точное анатомическое расположение FFA варьируется у разных участников, эта активация часто не достигает значимости при анализе случайных эффектов даже при значительном количестве зрячих участников. Таким образом, чтобы визуализировать среднее местоположение селективных активаций лица в каждой группе, каждый воксель был закодирован цветом в соответствии с количеством участников, показывающих выборочную активацию в этом вокселе.
Данные состояния покоя были предварительно обработаны с помощью набора инструментов CONN (https://www.nitrc.org/projects/conn). Структурные данные были сегментированы и нормализованы. Функциональные данные были скорректированы по движению, и была проведена регрессия мешающих факторов для удаления артефактов движения головы и сигналов желудочков и белого вещества. Порог движения объекта был установлен на 0,9 мм, чтобы исключить моменты времени с сильным движением. После этого данные состояния покоя фильтровали полосовым фильтром (от 0,009 до 0,08 Гц). Все данные проецировались на поверхность fsaverage с помощью Freesurfer (freesurfer.net) для дальнейшего анализа.
Анализ FROI в веретенообразной форме.
Мы использовали анализ FROI у зрячих и слепых для количественной оценки избирательности лиц. В частности, мы использовали ранее опубликованные (49) участки с анатомическими ограничениями, загруженные с https://web.mit.edu/bcs/nklab/GSS.shtml, внутри которых определяли FFA. Эти посылки проецировались на родной том каждого испытуемого. Избирательная по лицу ROI для каждого субъекта была определена как верхние n вокселей в пределах анатомического ограничивающего пакета для FFA, которые наиболее значимо реагировали на лицо по сравнению с стимулами лабиринта, руки и стула (независимо от того, достигли ли какие-либо из этих вокселей любой статистический критерий).Мы зафиксировали n как 50 верхних вокселей (или 400 мм 3 ) до анализа данных, но также изменили от 10 до 150 вокселей (т. Е. От 80 до 1200 мм 3 ) для оценки селективности как функции Размер ROI. Мы всегда использовали независимые данные для выбора верхних вокселей и оценки активаций (на основе процедуры перекрестной проверки нечетных и четных результатов), чтобы избежать двойного погружения. Расчетные бета-значения были преобразованы в жирные процентные значения изменения сигнала путем деления на средний уровень сигнала (см. Приложение SI, приложение , рис.S5 для анализа исходных бета-оценок вместо процентного изменения сигнала). Статистическая значимость оценивалась с помощью двусторонних парных тестов t между категориями объектов по субъектам.
Прогнозирование на основе CF.
Этот анализ проверяет, насколько хорошо мы можем предсказать функциональные активации у каждого участника на основании данных корреляции фМРТ в состоянии покоя, используя подход, описанный Osher et al. (65). Этот метод является вариантом метода, используемого в исх. 57, 64 и 79, но применительно к данным фМРТ в состоянии покоя.Вкратце, мы использовали мультимодальные фрагменты Glasser из Human Connectome Project (66) для определения целевой области (внутри веретенообразной формы) и областей поиска (остальных участков). Веретенообразная целевая область в каждом полушарии включала следующие пять участков Глассера в каждом полушарии: область V8, веретенообразный комплекс лица, область TF, область PHT и вентральный зрительный комплекс. Затем мы определили CF для каждой вершины веретенообразной целевой области. CF каждой вершины представлял собой 355-мерный вектор, каждое измерение представляло корреляцию Пирсона между ходом времени этой вершины в состоянии покоя и ходом времени одного из 355 оставшихся участков Glasser в пространстве поиска во время того же сканирования в состоянии покоя ( усредненное по всем вершинам в выбранном целевом участке Glasser).
Прогнозирующая модель.
Затем мы обучили модель гребневой регрессии для прогнозирования избирательности лица каждого воксела в веретенообразной целевой области непосредственно из CF (65). Т-статистическая карта по контрасту лица> лабиринта, руки и стула использовалась для прогнозов, как и в предыдущих исследованиях (57, 64, 65). Модель была обучена с использованием стандартизованных данных (среднее значение по всем вершинам в веретенообразном пространстве поиска и единичное стандартное отклонение) с использованием процедуры перекрестной проверки с исключением одного субъекта и исключения.Этот метод гарантирует, что прогнозируемые данные индивидуального субъекта никогда не будут использоваться в процедуре обучения. Модель гребневой регрессии включает параметр регуляризации λ, который был определен с помощью перекрестной проверки «оставление одного субъекта» во внутреннем цикле. Каждый внутренний цикл повторялся 100 раз, каждый с различным коэффициентом λ (значения λ логарифмически разнесены между 10 -5 и 10 2 ). Оптимальные λs и βs были выбраны из моделей внутреннего цикла, которые минимизировали среднеквадратическую ошибку между предсказанными и наблюдаемыми значениями активации, и использовались для прогнозирования ответов для удерживаемого субъекта.Точность прогнозирования модели оценивалась как корреляция Пирсона между прогнозируемыми и наблюдаемыми моделями избирательности лица по вершинам в веретенообразных целевых областях для каждого субъекта. Мы сравнили прогнозы модели с эталонными прогнозами, полученными при групповом анализе случайных эффектов, с использованием общей линейной модели (в Freesurfer), примененной к избирательности по лицам других субъектов.
Процедуры обучения модели и тестирования были аналогичны Osher et al.(65), за исключением одного важного различия. Мы разделили все функциональные данные и данные о состоянии покоя на две независимые группы (разделение на четные и нечетные прогоны). Мы обучили все наши модели на основе данных четных запусков и оценили производительность моделей на основе данных нечетных запусков. Эта дополнительная процедура гарантирует, что прогнозы для каждого субъекта являются независимыми выборками для последующего статистического анализа. Статистическая значимость оценивалась с использованием двусторонних парных тестов t на оценках предсказаний, преобразованных Фишером для разных субъектов.Чтобы оценить степень, в которой мы можем предсказать функциональную активацию от участков в отдельных долях, мы разделили области поиска на лобные, теменные, затылочные и височные доли на основе участков Глассера (66). Эти области включали 162, 66, 60 и 67 участков в лобной, теменной, затылочной и височной областях соответственно. Мы переобучили наши модели с нуля, ограничивая предикторы участками в каждой доле, оценили производительность модели и выполнили статистические тесты, как и раньше.
Доступность данных.
Все данные исследования включены в основной текст SI и Приложение .
Благодарности
Авторы хотели бы поблагодарить Линдси Яццолино и Марину Бедни за вдумчивые обсуждения и отзывы, а также Джоба Ван дер Херка и Ханса оп де Бека за любезно предоставленные слуховые стимулы, использованные в их исследовании. Эта работа была поддержана грантом NIH Shared Instrumentation Grant (S10OD021569) Центру Athinoula Martinos в Массачусетском технологическом институте, учебным грантом Национального института глазных болезней (5T32EY025201-03) и грантом Исследовательского центра инженерной реабилитации Института исследований глаза Smith-Kettlewell S.T., Стипендия факультета военно-морских исследований Ванневара Буша (N00014-16-1-3116) для AO, награда NIH Pioneer Award (NIH DP1HD091957) для NK и Научно-технический центр NSF — Центр мозга, разума и Машины Гранта (NSF CCF-1231216).
Сноски
Вклад авторов: N.A.R.M., S.T., A.O. и N.K. спланированное исследование; N.A.R.M., S.T., D.B. и A.M. проведенное исследование; N.A.R.M., S.T., D.B. и A.M. проанализированные данные; и Н.А.Р.М., С.Т., А.О. и Н.К.написал газету.
Рецензенты: D.A.L., Национальный институт психического здоровья; и H.O.d.B., Левенский университет.
Авторы заявляют об отсутствии конкурирующей заинтересованности.
Эта статья содержит вспомогательную информацию в Интернете по адресу https://www.pnas.org/lookup/suppl/doi:10.1073/pnas.2004607117/-/DCSupplemental.
Основы принятия этических решений
ВЫБОР: ОСНОВА ДЛЯ ПРИНЯТИЯ ЭТИЧЕСКИХ РЕШЕНИЙ
Решения о правильном и неправильном пронизывают повседневную жизнь.Этика должна касаться всех уровней жизни: действовать правильно как отдельные личности, создавать ответственные организации и правительства и делать наше общество в целом более этичным. Этот документ разработан как введение в принятие этических решений. Он признает, что решения о «правильном» и «неправильном» могут быть трудными и могут быть связаны с индивидуальным контекстом. Сначала приводится краткое изложение основных источников этического мышления, а затем представлена структура для принятия решений.
1.ЧТО ТАКОЕ ЭТИКА? :
Этика предоставляет набор стандартов поведения, которые помогают нам решить, как нам следует действовать в различных ситуациях. В некотором смысле мы можем сказать, что этика — это все, чтобы делать выбор и указывать причины, по которым мы должны делать этот выбор.
Этику иногда путают или путают с другими способами принятия решений, включая религию, закон или мораль. Многие религии поощряют принятие этических решений, но не всегда рассматривают весь спектр этических решений, с которыми мы сталкиваемся.Религии могут также пропагандировать или запрещать определенные виды поведения, которые могут не считаться надлежащей сферой этики, например ограничения в питании или сексуальное поведение. Хорошая система права должна быть этичной, но закон создает прецедент, пытаясь диктовать универсальные руководящие принципы, и, таким образом, не может реагировать на индивидуальный контекст. Закону может быть сложно разработать или обеспечить соблюдение стандартов в некоторых важных областях, и он может медленно решать новые проблемы. И закон, и этика имеют дело с вопросами о том, как мы должны жить вместе с другими, но иногда считается, что этика применима и к тому, как люди действуют, даже когда другие не участвуют. Наконец, многие люди используют термины мораль и этика как синонимы. Другие оставляют мораль для состояния добродетели, рассматривая этику как кодекс, который делает возможной мораль. Еще один способ подумать о взаимосвязи между этикой и моралью — это увидеть в этике рациональную основу морали, то есть этика дает веские причины того, почему что-то является моральным.
2. ТРАДИЦИОННОЕ ОБОРУДОВАНИЕ В ОБЛАСТИ ЭТИКИ :
Существует множество этических систем и множество способов думать о правильных и неправильных действиях или о хорошем и плохом характере.Сфера этики традиционно делится на три области: 1.) метаэтика, которая имеет дело с природой права или блага, а также с природой и обоснованием этических требований; 2) нормативная этика, которая касается стандартов и принципов, используемых для определения того, является ли что-то правильным или хорошим; 3.) прикладная этика, которая касается фактического применения этических принципов в конкретной ситуации. Хотя полезно подходить к области этики именно в таком порядке, мы могли бы иметь в виду, что этот несколько подход «сверху вниз» не исчерпывает изучение этики.Наш опыт применения определенных этических стандартов или принципов может помочь нам понять, насколько хороши эти стандарты или принципы.
Три широких типа этической теории:
Этические теории часто делятся на три типа: i) теории консеквенциализма, которые в первую очередь касаются этических последствий конкретных действий; ii) теории, не связанные с консеквенциализмом, которые, как правило, в основном связаны с намерениями человека, принимающего этические решения относительно конкретных действий; и iii) агентно-центрированные теории, которые, в отличие от консеквенциалистских и неконсеквенциалистских теорий, больше озабочены общим этическим статусом индивидов или агентов и меньше озабочены выявлением морали конкретных действий.Каждая из этих трех широких категорий содержит различные подходы к этике, некоторые из которых имеют общие характеристики для разных категорий. Ниже приведены некоторые из наиболее важных и полезных из этих этических подходов.
i.) Консеквенциалистские теории :
Утилитаристский подход
Утилитаризм восходит к школе древнегреческого философа Эпикура Самосского (341–270 гг. До н. Э.), Который утверждал, что лучшая жизнь — это та, которая причиняет меньше всего боли и страданий.Британский философ Джереми Бентам (1748-1832), британский философ 18-го -го века года, применил аналогичный стандарт к индивидуальным действиям и создал систему, в которой действия могут быть описаны как хорошие или плохие в зависимости от количества и степени удовольствия и / или боли, которые они испытывают. будет производить. Ученик Бентама, Джон Стюарт Милль (1806-1873) изменил эту систему, сделав ее стандартом блага более субъективным понятием «счастье», в отличие от более материалистического представления о «удовольствии».
Утилитаризм — один из наиболее распространенных подходов к принятию этических решений, особенно решений с последствиями, которые затрагивают большие группы людей, отчасти потому, что он инструктирует нас взвешивать различные количества хорошего и плохого, которые будут произведены нашими действиями.Это соответствует нашему чувству, что некоторые хорошие и плохие обязательно будут результатом наших действий и что лучшим действием будет то, которое принесет больше всего пользы или принесет наименьший вред, или, другими словами, создаст наибольший баланс. добра над вредом. Таким образом, этические экологические действия приносят наибольшую пользу и наносят наименьший вред всем, кого затрагивают: правительству, корпорациям, сообществу и окружающей среде.
Эгоистический подход
Один из вариантов утилитарного подхода известен как этический эгоизм или этика личных интересов.При таком подходе человек часто использует утилитарный расчет, чтобы произвести наибольшее количество благ для себя. Древнегреческие софисты, такие как Фразимак (ок. 459–400 до н. Э.), Которые, как известно, утверждали, что сила делает правильным, и ранние современные мыслители, такие как Томас Гоббс (1588–1679), могут считаться предшественниками этого подхода. Одним из самых влиятельных сторонников этического эгоизма в последнее время была русско-американский философ Айн Рэнд (1905-1982), которая в книге The Virtue of Selfishness (1964) утверждает, что личный интерес является предпосылкой для самореализации. уважение и уважение к другим.Существует множество параллелей между этическим эгоизмом и экономическими теориями невмешательства, в которых преследование личных интересов рассматривается как ведущее к благу общества, хотя благо общества рассматривается только как удачный побочный продукт следования личным личным интересам. , а не его цель.
Подход общего блага
Древнегреческие философы Платон (427–347 до н. Э.) И Аристотель (384–322 до н. Э.) Придерживались точки зрения, согласно которой наши действия должны способствовать этической общественной жизни.Самым влиятельным современным сторонником этого подхода был французский философ Жан-Жак Руссо (1712-1778), который утверждал, что лучшее общество должно руководствоваться «общей волей» людей, которая затем производит то, что лучше для людей. в целом. Такой подход к этике подчеркивает сетевые аспекты общества и подчеркивает уважение и сострадание к другим, особенно к тем, кто более уязвим.
ii.) Неконсвенциалистские теории :
Подход, основанный на долге
Подход, основанный на долге, иногда называемый деонтологической этикой, чаще всего ассоциируется с философом Иммануилом Кантом (1724-1804 гг.), Хотя у него были важные предшественники в более раннем неконсвенциалистском, часто явно религиозном, думать о таких людях, как святой Августин Гиппопотам (354–430), который подчеркивал важность личной воли и намерения (и всемогущего Бога, который видит это внутреннее ментальное состояние) для принятия этических решений.Кант утверждал, что правильные поступки связаны не с последствиями наших действий (чем-то, что мы в конечном итоге не можем контролировать), а с правильным намерением при выполнении действия. Этическое действие является следствием долга, то есть совершается именно потому, что это наша обязанность. Этические обязательства одинаковы для всех разумных существ (они универсальны), и знание того, что они влекут за собой, достигается путем открытия правил поведения, которым не противоречит разум.
Известная формула Канта для открытия нашего этического долга известна как «категорический императив». У него есть несколько различных версий, но Кант считал, что все они сводятся к одному и тому же императиву. Самая основная форма повеления такова: «Действуйте только в соответствии с той максимой, по которой вы в то же время можете пожелать, чтобы она стала универсальным законом». Так, например, ложь неэтична, потому что мы не можем универсализировать максиму, гласящую: «Всегда нужно лгать». Такая максима сделала бы все речи бессмысленными.Однако мы можем универсализировать максиму «Всегда говори правдиво», не впадая в логическое противоречие. (Обратите внимание, что подход, основанный на долге, ничего не говорит о том, насколько легко или сложно было бы выполнять эти максимы, только то, что это наш долг как разумных существ.) Действуя в соответствии с законом, который, как мы обнаружили, является рациональным. в соответствии с нашим собственным универсальным разумом мы действуем автономно (саморегулирующимся образом) и, таким образом, связаны своим долгом — долгом, который мы возложили на себя как на разумные существа.Таким образом, мы свободно выбираем (мы будет ), чтобы связать себя моральным законом. Для Канта выбор повиновения универсальному моральному закону является самой природой этичного поведения.
Правозащитный подход
Правозащитный подход к этике — это еще один неконсеквенциалистский подход, который в значительной степени черпает свою нынешнюю силу из кантовской этики, основанной на долге, хотя его история восходит, по крайней мере, к стоикам Древней Греции и Рим, и имеет другое влиятельное течение, которое вытекает из работ британского философа-эмпирика Джона Локка (1632–1704).Этот подход предусматривает, что наилучшее этическое действие — это то, что защищает этические права тех, на кого это действие влияет. Он подчеркивает веру в то, что все люди имеют право на достоинство. Это основано на формулировке категорического императива Канта, который гласит: «Действуйте так, чтобы относиться к человечеству, будь то в себе или в лице другого человека, всегда одновременно как цель и никогда просто как средство. к концу.» Список этических прав обсуждается; многие сейчас утверждают, что животные и другие нечеловеческие существа, такие как роботы, также имеют права.
Подход справедливости или справедливости
Кодекс законов Хаммурапи в Древней Месопотамии (ок. 1750 г. до н.э.) постановил, что со всеми свободными людьми следует обращаться одинаково, так же как со всеми рабами следует обращаться одинаково. В сочетании с универсальностью правового подхода подход справедливости может применяться ко всем людям. Наиболее влиятельная версия этого подхода сегодня находится в работе американского философа Джона Ролза (1921-2002), который утверждал, в соответствии с кантианскими принципами, что именно этические принципы — это те принципы, которые были бы выбраны свободными и рациональными людьми в исходной ситуации. равенства.Этот гипотетический контракт считается справедливым или просто потому, что он обеспечивает процедуру того, что считается справедливым действием, и не касается последствий этих действий. Справедливость отправной точки — это принцип того, что считается справедливым.
Подход Божественного Повеления
Как следует из названия, этот подход рассматривает то, что правильно, как то, что заповедует Бог, а этические стандарты являются творением Божьей воли. Следование воле Бога рассматривается как само определение этичного.Поскольку Бог рассматривается как всемогущий и обладающий свободной волей, Бог может изменить то, что сейчас считается этичным, и Бог не связан никакими стандартами правильного или неправильного, за исключением логического противоречия. Средневековый христианский философ Уильям Оккам (1285–1349) был одним из самых влиятельных мыслителей этой традиции, и его труды служили руководством для протестантских реформаторов, таких как Мартин Лютер (1483–1546) и Жан Кальвин (1509–1564). Датский философ Сорен Кьеркегор (1813-1855), восхваляя готовность библейского патриарха Авраама убить своего сына Исаака по повелению Бога, утверждал, что истинно правильные действия должны в конечном итоге выйти за рамки повседневной морали и перейти к тому, что он назвал «телеологической приостановкой этического »Снова демонстрируя несколько слабую связь между религией и этикой, упомянутую ранее.
iii.) Агентно-центрированные теории :
Подход добродетели
Один давний этический принцип утверждает, что этические действия должны согласовываться с идеальными человеческими добродетелями. Аристотель, например, утверждал, что этика должна касаться всей жизни человека, а не отдельных отдельных действий, которые человек может совершить в любой данной ситуации. Человек с хорошим характером — это тот, кто достиг определенных добродетелей. Этот подход также заметен в незападных контекстах, особенно в Восточной Азии, где традиция китайского мудреца Конфуция (551-479 гг. До н.э.) подчеркивает важность добродетельных действий (надлежащим образом) в различных ситуациях.Поскольку этика добродетели касается всей жизни человека, она серьезно относится к процессу образования и обучения и подчеркивает важность ролевых моделей для нашего понимания того, как участвовать в этических дискуссиях.
Феминистский подход
В последние десятилетия добродетельный подход к этике дополнялся, а иногда и значительно пересматривался мыслителями феминистской традиции, которые часто подчеркивали важность опыта женщин и других маргинализированных групп для этического обсуждения.Одним из наиболее важных вкладов этого подхода является то, что он выдвигает на первый план принцип заботы как законно основную этическую заботу, часто в противоположность, казалось бы, холодному и безличному подходу к справедливости. Как и этика добродетели, феминистская этика касается всей человеческой жизни и того, как эта жизнь влияет на то, как мы принимаем этические решения.
Прикладная этика
Термины, используемые в этических суждениях
Прикладная этика касается вопросов частной или общественной жизни, которые являются предметом этических суждений.Ниже приведены важные термины, используемые при вынесении моральных суждений о конкретных действиях.
Обязательно: Когда мы говорим, что что-то этически «обязательно», мы имеем в виду, что это не только правильно, но и неправильно не делать этого. Другими словами, у нас есть этическое обязательство выполнить действие. Иногда самый простой способ узнать, является ли действие этически обязательным, — это посмотреть, что означало бы НЕ выполнять действие. Например, мы могли бы сказать, что забота о своих детях является этически обязательной для родителей не только потому, что это правильно для них, но также потому, что для них неправильно не делать этого.Дети пострадают и умрут, если родители не будут о них заботиться. Таким образом, родители этически «обязаны» заботиться о своих детях.
Недопустимо: Противоположностью этически обязательного действия является действие, которое этически недопустимо, что означает, что делать это неправильно и правильно не делать. Например, мы бы сказали, что убийство недопустимо с этической точки зрения.
Допустимые: Иногда действия называются этически допустимыми или этически «нейтральными», потому что совершать или не делать их ни правильно, ни неправильно.Мы могли бы сказать, что проведение пластической хирургии этически допустимо, потому что операция не является неправильной (это не недопустимо), но и не является этически необходимой (обязательной) операцией. Некоторые утверждают, что самоубийство допустимо при определенных обстоятельствах. То есть человек не ошибется, если совершит самоубийство, и не ошибется, если не совершит самоубийство. Другие сказали бы, что самоубийство недопустимо с этической точки зрения.
Сверхподчинение: Четвертый тип этического действия называется сверхнормативным.Подобные действия рассматриваются как выходящие за рамки служебного долга. Они поступают правильно, но не делать их неправильно. Например, два человека идут по коридору и видят, как третий бросает их сумку с книгами, рассыпая все их книги и бумаги на пол. Если один человек останавливается, чтобы помочь третьему человеку забрать свои книги, но другой продолжает идти, мы каким-то образом чувствуем, что человек, который остановился, чтобы помочь, действовал более этически приемлемым образом, чем человек, который не останавливался, но мы не могу сказать, что человек, который не остановился, поступил неэтично, не остановившись.Другими словами, человек, который не помог, никоим образом не был обязан (это не было этически обязательным) помогать. Но мы, тем не менее, хотим с этической точки зрения похвалить человека, который остановился, поэтому мы называем его или ее действия чрезмерными.
3. ОСНОВЫ ПРИНЯТИЯ ЭТИЧЕСКИХ РЕШЕНИЙ :
Принятие правильных этических решений требует обученного восприятия этических вопросов и отработанного метода изучения этических аспектов решения и взвешивания соображений, которые должны повлиять на наш выбор курса действий.Важно иметь метод принятия этических решений. При регулярной практике метод становится настолько привычным, что мы работаем с ним автоматически, не обращая внимания на конкретные шаги. Это одна из причин, по которой мы иногда можем сказать, что у нас есть «моральная интуиция» относительно определенной ситуации, даже если мы не продумали ее сознательно. Мы привыкли выносить этические суждения, точно так же, как мы можем научиться играть на пианино и можем хорошо сидеть и играть, «не задумываясь». Тем не менее, не всегда рекомендуется следовать нашей непосредственной интуиции, особенно в особо сложных или незнакомых ситуациях.Здесь наш метод принятия этических решений должен позволить нам распознавать эти новые и незнакомые ситуации и действовать соответственно.
Чем новее и труднее стоит перед нами этический выбор, тем больше нам нужно полагаться на обсуждение и диалог с другими о дилемме. Только путем тщательного изучения проблемы, опираясь на мнения и различные точки зрения других, мы можем сделать правильный этический выбор в таких ситуациях.
Три концепции
Основываясь на разделении на три части традиционных нормативных этических теорий, о которых говорилось выше, имеет смысл предложить три широкие концепции для руководства принятием этических решений: концепция консеквенциализма; Структура обязанностей; и рамки добродетели.
Хотя каждая из трех концепций полезна для принятия этических решений, ни одна из них не идеальна — иначе совершенная теория давно бы вытеснила другие несовершенные теории. Знание преимуществ и недостатков фреймворков поможет решить, какая из них наиболее полезна в подходе к конкретной ситуации, с которой мы сталкиваемся.
Концепция консеквенциализма
В рамках концепции консеквенциализма мы сосредотачиваемся на будущих эффектах возможных вариантов действий, учитывая людей, которые будут прямо или косвенно затронуты.Мы спрашиваем, какие результаты желательны в данной ситуации, и считаем, что этичным поведением является то, что приведет к наилучшим результатам. Человек, использующий структуру «Последствия», желает производить как можно больше пользы.
Одним из преимуществ этой этической основы является то, что сосредоточение внимания на результатах действия является прагматическим подходом. Это помогает в ситуациях, в которых участвует много людей, некоторые из которых могут извлечь выгоду из действия, а другие — нет. С другой стороны, не всегда можно предсказать последствия действия, поэтому некоторые действия, которые, как ожидается, приведут к положительным последствиям, могут в конечном итоге навредить людям.Кроме того, люди иногда негативно реагируют на использование компромисса, которое является неотъемлемой частью этого подхода, и отшатываются от того, что цель оправдывает средства. Он также не включает заявление о том, что определенные вещи всегда неправильны, поскольку даже самые отвратительные действия могут привести к хорошему результату для некоторых людей, и эта структура позволяет таким действиям быть этичными.
Структура обязанностей
В структуре обязанностей мы фокусируемся на обязанностях и обязательствах, которые у нас есть в данной ситуации, и рассматриваем, какие этические обязательства у нас есть, а чего мы никогда не должны делать.Этическое поведение определяется выполнением своих обязанностей и правильными поступками, а целью является выполнение правильных действий.
Эта структура имеет то преимущество, что создает систему правил, которая соответствует ожиданиям всех людей; если действие является этически правильным или требуется обязанность, оно применимо к каждому человеку в данной ситуации. Эта беспристрастность побуждает относиться ко всем с равным достоинством и уважением.
Эта концепция также фокусируется на следовании моральным правилам или долгу независимо от результата, поэтому она допускает возможность того, что кто-то мог действовать этично, даже если результат плохой.Следовательно, эта структура лучше всего работает в ситуациях, когда есть чувство обязательства, или в тех, в которых нам нужно учитывать, почему долг или обязательство предписывает или запрещает определенные действия.
Однако эта структура также имеет свои ограничения. Во-первых, он может показаться холодным и безличным, поскольку может потребовать действий, которые, как известно, причиняют вред, даже если они строго соответствуют определенному моральному правилу. Это также не дает способа определить, какую обязанность мы должны выполнять, если мы сталкиваемся с ситуацией, в которой две или более обязанности противоречат друг другу.Он также может быть жестким в применении понятия долга ко всем, независимо от личной ситуации.
Структура добродетели
В рамках концепции добродетели мы пытаемся определить черты характера (положительные или отрицательные), которые могут мотивировать нас в данной ситуации. Нас волнует, какими людьми мы должны быть и что наши действия говорят о нашем характере. Мы определяем этическое поведение как то, что добродетельный человек поступил бы в данной ситуации, и мы стремимся развивать подобные добродетели.
Очевидно, этот фреймворк полезен в ситуациях, когда задают вопрос, каким человеком следует быть. Как способ осмыслить мир, он позволяет называть этическим широкий спектр поведения, поскольку может быть много разных типов хорошего характера и множество путей его развития. Следовательно, он принимает во внимание все аспекты человеческого опыта и их роль в этических размышлениях, поскольку считает, что все переживания, эмоции и мысли могут влиять на развитие характера.
Хотя эта схема учитывает различный человеческий опыт, она также затрудняет разрешение споров, поскольку часто может быть больше разногласий по поводу добродетельных качеств, чем этических действий. Кроме того, поскольку структура смотрит на характер, она не особенно хороша для того, чтобы помочь кому-то решить, какие действия предпринять в данной ситуации, или определить правила, которыми будут руководствоваться эти действия. Кроме того, поскольку он подчеркивает важность ролевых моделей и образования для этического поведения, иногда он может просто укрепить существующие культурные нормы как стандарт этического поведения.
Объединение рамок
Обозначая ситуацию или выбор, с которыми вы сталкиваетесь, одним из представленных выше способов, можно более четко выделить конкретные особенности. Однако следует отметить, что у каждой структуры есть свои ограничения: если сосредоточить внимание на одном наборе функций, другие важные функции могут быть скрыты. Следовательно, важно знать все три концепции и понимать, как они соотносятся друг с другом — где они могут пересекаться, а где могут отличаться.
Приведенная ниже таблица предназначена для выделения основных различий между тремя системами:
Консеквенциалист | Дежурный | Добродетель | |
D Отборочный процесс | Какие результаты я должен получить (или попытаться добиться)? | Каковы мои обязанности в этой ситуации и чего мне никогда не следует делать? | Каким человеком я должен быть (или стараться быть), и что мои действия скажут о моем характере? |
Фокус | Обращает внимание на будущие последствия действия для всех людей, на которых это действие прямо или косвенно повлияет. | Обращает внимание на обязанности, которые существуют до ситуации, и определяет обязанности. | Попытки различить черты характера (достоинства и пороки), которые являются или могли бы мотивировать людей, вовлеченных в ситуацию. |
Определение этического поведения | Этическое поведение — это действие, которое приведет к наилучшим последствиям. | Этичное поведение предполагает всегда поступать правильно: никогда не нарушать свой долг. | Этическое поведение — это то, что добродетельный человек поступил бы в данных обстоятельствах. |
Мотивация | Цель — производить как можно больше хорошего. | Цель — совершить правильное действие. | Цель — развить характер. |
───
Поскольку ответы на три основных типа этических вопросов, задаваемых каждой структурой, не исключают друг друга, каждая структура может быть использована для достижения хотя бы некоторого прогресса в ответах на вопросы, поставленные двумя другими.
Во многих ситуациях все три схемы приводят к одним и тем же — или, по крайней мере, очень похожим — выводам о том, что вы должны делать, обычно приводят разные причины для таких выводов .
Однако, поскольку они сосредоточены на разных этических особенностях, выводы, сделанные с помощью одной концепции, будут иногда отличаться от выводов, сделанных с помощью одной (или обеих) других.
4.ПРИМЕНЕНИЕ РАМКИ К СЛУЧАЯМ:
При использовании структур для вынесения этических суждений по конкретным случаям будет полезно следовать приведенному ниже процессу.
Распознавание этической проблемы
Одна из самых важных вещей, которую нужно сделать в начале этического обсуждения, — это выявить, насколько это возможно, специфические этические аспекты рассматриваемой проблемы. Иногда то, что кажется этическим спором, на самом деле является спором о фактах или концепциях.Например, некоторые утилитаристы могут утверждать, что смертная казнь этична, потому что она сдерживает преступность и, таким образом, приносит наибольшую пользу при наименьшем вреде. Однако другие утилитаристы могут возразить, что смертная казнь не удерживает преступников и, таким образом, приносит больше вреда, чем пользы. Аргумент здесь заключается в том, какие факты говорят в пользу морали конкретного действия, а не просто в пользу морали определенных принципов. Все утилитаристы придерживались бы принципа приносить наибольшее благо при наименьшем вреде.
Учитывайте вовлеченные стороны
Еще один важный аспект, о котором следует подумать, — это различные лица и группы, на которых может повлиять ваше решение. Подумайте, кому может быть причинен вред, а кому может быть выгодно.
Соберите всю релевантную информацию
Прежде чем предпринимать какие-либо действия, рекомендуется убедиться, что вы собрали всю необходимую информацию и что были изучены все потенциальные источники информации.
Сформулируйте действия и рассмотрите альтернативы
Оцените варианты принятия решений, задав следующие вопросы:
Какое действие принесет наибольшую пользу и наименьший вред? (Утилитарный подход)
Какое действие уважает права всех, кто участвует в принятии решения? (Правозащитный подход)
Какое действие относится к людям одинаково или пропорционально? (Правосудие подход)
Какое действие служит сообществу в целом, а не только отдельным участникам?
(Подход общего блага)
Какое действие заставляет меня действовать как человек, которым я должен быть? (Подход добродетели)
Примите решение и рассмотрите его
После изучения всех возможных действий, какое действие лучше всего подходит для ситуации? Как я отношусь к своему выбору?
Act
Многие этические ситуации вызывают дискомфорт, потому что мы никогда не можем получить всю информацию.Даже в этом случае мы должны часто действовать.
Размышляйте о результате
Каковы были результаты моего решения? Каковы были запланированные и непредвиденные последствия? Мог бы я что-нибудь изменить сейчас, когда увидел последствия?
5. ВЫВОДЫ :
Принятие этических решений требует чуткости к этическим последствиям проблем и ситуаций. Это также требует практики. Очень важно иметь основу для принятия этических решений.Мы надеемся, что приведенная выше информация поможет вам развить собственный опыт в принятии решений.
Благодарности:
Эта основа этического мышления является продуктом диалога и дебатов на семинаре Делая выбор: этические решения на рубеже глобальной науки , проведенном в Университете Брауна в весеннем семестре 2011 года. Он основан на этических основах, разработанных в Центре Марккула. для прикладной этики в Университете Санта-Клары и этических рамок, разработанных Центром этических дискуссий в Университете Северного Колорадо, а также этических рамок для принятия академических решений на сайте Faculty Focus, который, в свою очередь, опирается на понимание этических основ для E -Принятие решения об обучении, 1 декабря 2008 г.